tl;dr: I think it’s time we rethink a lot of how we document computational work. Prompted by AI but also just general increasing complexity of software, we need to move from documenting how something came to be towards documenting what that something is. This more practical form of documentation will allow us to focus our efforts on what matters scientifically.
It has long been held as sacrosanct that proper scientific reporting requires documenting the provenance of any particular output. To translate: if you want to share something—an experimental result, whatever—you have to describe exactly how you did it, every step of the way.
This same sentiment has been applied to computational analyses. Given the potential (and I emphasize potential) to provide an exact record of what was done, it has been a long standing goal to provide code that provides an immutable record of the path from the data to the figures in the paper. But this paradigm has started to seem both less ideal and less practical in the modern software environment, even more so with the advent of large statistical models (“AI”).
The issue is that somewhere along the way, software became a lot more like a living organism than a static entity. Virtually all software depends on a maze of interdependent packages, and despite many attempts, like environments and docker containers and whatever, there’s really no way to avoid the fact that keeping software valid and runnable requires ongoing maintenance work. Machine learning models compound this problem. These models are largely inscrutable, and their black box outputs can vary due to from seemingly minor changes in the prompting or other input. What do we do?
I think the solution is to document based on function. What I mean is that we should focus more on documenting our software by verifying its output than worrying about every parameter that goes into it. For example: in image analysis, a key problem has always been segmentation, meaning how you identify (i.e., circle) cells for quantification. Everybody had their own algorithm and would pass around scripts to document the pipeline. The thing is… nobody really cared all that much about the algorithms, most of which were completely specific to the particular dataset. What we cared about a lot more about (or at least should have cared more about) was the quality of the output. How good was the segmentation? What were the false positives and negatives? What were the failure modes and how might that affect the downstream analysis? I think we would do a lot better trying to focus on that aspect of documenting our science. For instance, with machine learning tools, image analysis has undergone a major transformation, with these models having an uncanny ability to segment cells now and automate analyses that were previously unthinkable. Thing is, people retrain all their own local models, and minor parameters change, and at some point… who cares? It’s wasted effort to keep track of the details, and far more important to know whether the output is right. So let’s document that verification.
Same applies in genomic data analysis. Genomic analyses often depend on a large number of parameters that can vary from dataset to dataset. Documenting these is important, but honestly, I think it’s a bit beside the point. The main thing is not the precise thresholds and parameters that went into your peak-finding algorithm, but rather the plain fact of whether it actually found your peaks correctly.
This discussion may remind you of unit testing, in which you put your software through a suite of tests to make sure each part does the right thing. The whole idea is to verify what the code does and not how it does it. So not a new concept at all.
The use of LLMs is another example of how difficult and, ultimately, futile it is to insist on documentation by provenance. Let’s say I ask ChatGPT to help me figure out the pathway that corresponds to the activity of a list of gene names. Now, maybe I’ll get the same answer if I run it again next week, or maybe not. Does it matter? I don’t think so, as long as the answer is verified as being right.
By the way, experimental documentation often does the same thing wherever possible. Take, for instance, plasmids. Yes, I am old enough to remember reading through methods sections to learn some fun cloning tricks. But mostly… who cares? If I get the plasmid from AddGene, I don’t usually care one bit how the pieces were put together or what kind of prep kit you used. What I care about is the plasmids actual sequence—verification based on function rather than provenance. If you look around, you’ll see that whenever it is possible, people will use this mode of verification, with things like certificates of analysis and whatever. Experienced researchers also know that you can’t trust methods sections. For instance, if you read about a drug at a particular concentration, you typically have to do the dose curve in house. It’s not something shady, just the way it is. Verification by provenance is just what we do when we don’t have any other alternative.
So where does this leave us? A couple ideas:
Visualize and document intermediates. Human or computer verification of intermediate stages of the analysis pipeline. Show the reader that your spot detection algorithm is accurately finding spots, or that your RNA-seq analysis is accurately counting reads.
Journals should focus on software verification rather than just software availability. Lots of published software just plain doesn’t run. I don’t doubt that the software probably did run at some point. It’s just really hard to keep everything up to date. How can the journal verify in some way that the software actually did run and produces reasonable output? I’m not sure. Perhaps every paper must present some kind of battery of tests and the results of their algorithm’s performance in those tests?
Anyway, I don’t know the answers, but I do know that the problem of software validity is a growing problem, and one that is likely to get worse with the increasingly pervasive use of machine learning techniques for which completely documentation of provenance is far less valuable than documenting by function.
Showing posts with label how to do science. Show all posts
Showing posts with label how to do science. Show all posts
Monday, January 6, 2025
Wednesday, June 5, 2024
Project choice: Lean into your strengths
TL;DR: Projects are not entirely good or bad on their own. They have to match the person doing them: you! Be honest with yourself about what your strengths and passions are. Choose a project that is fundamentally aligned with those strengths. Do NOT choose a project that relies heavily on things you are not intrinsically motivated to do. You may be tempted to pick a project to shore up on weaknesses, but don’t. Any project will have aspects that will require you to work on your weaknesses, but a project that is fundamentally aligned with your weaknesses is going to be an exercise in misery.
One of the most common questions I get from new students is how to choose a scientific project. Clearly a super important part of the scientific process, but one that has had a somewhat magical quality to it, as though there is some magic wand that one waves over a set of eppendorf tubes to turn them into a preprint that everyone wants to read. Of course, many scientists have some introspection and insight into their thought processes, and while that has largely been passed on by word of mouth, there have been some wonderful recent efforts to describe project ideation (creativity), selection, and execution (see work from Itai Yanai/Martin Lorsch, Uri Alon, Michael Fischbach, and probably several others I’m missing with apologies).
But I feel like a lot of this discussion has missed one critical feature: you. As in you, the one actually doing the project. Everyone has different strengths and weaknesses as a scientist, or more relevantly, passions and aversions. In my experience, which I’m sure many have shared, it’s the match between the project and the scientist that matters far more than the project on its own.
Why does it matter so much? Here’s my theory. Academic research is a highly unstructured work environment. It is hard to quantify, on a daily, weekly, or even monthly basis, exactly what constitutes “progress”. As such, it relies very strongly on intrinsic motivation. As in, you really have to want to do something in order to put in the sustained effort required to actually do it, because it is very difficult to quantify progress from the outside to help force you to do things you don’t want to do. It is possible to force yourself to do things you don’t want in the short term, but if you are not fundamentally excited to do something, it is very hard to keep yourself motivated to do it in the medium-to-long term.
What does this mean in practice? I think it’s easier to see how it plays out by looking at common failure modes in person-project matching. One common thing I’ve seen is sometimes people feel like they need to build experimental skills even though they are fundamentally more interested in computational work, so they want to work on a project that has a significant experimental component. Then what happens is some version of the following: “I could do this experiment today, but it’s Thursday at 4pm. I’ll do it tomorrow. Oh wait, it’s Friday, now I should probably wait until Monday” and next thing you know a month goes by and the experiment still hasn’t gotten done. Sometimes, if you take the same person and give them a dataset, they’re like “I just need this analysis to finish running by 4pm, then I can run the next step, oh wouldn’t it be cool if XYZ were true, hold on let me try this…”. It’s hard to ascribe these delays or accelerations to any one particular decision, but in aggregate, they have an enormous compounding effect. Same sort of thing the other way around.
By the way, this doesn’t mean that you shouldn’t try things, especially early on. I worked in a lab for a summer after my first year of math grad school basically as an exercise in getting some exposure to experimental work, even though I thought I’d never EVER do it for my actual thesis work. Turns out I had a true passion for experiments. Been trying to lean into that ever since! But you have to continuously evaluate and be brutally honest with yourself about whether you’re doing what you’re doing because you really like it or because you think you should like it. I’ve found graduate students often get caught in the trap of working on what they think they should like instead of what they actually like.
This same reasoning affects choice of advisor, both graduate and postdoctoral, especially the latter. Pick an advisor who can help you build on your strengths, and not someone who specializes in your weaknesses. This is not to say that you can’t have complementary skills—especially for postdocs, it is often very fruitful to combine your skills from your PhD with a set of techniques in the postdoc lab. But if you join a lab where the advisor is a skilled computationalist but you want to do some cutting edge experiments, it must be done with a lot of care. You want to be sure the rest of the environment is strong, because it will be difficult for your advisor to guide you to innovate at the edge of the field given their own strengths and weaknesses. Not to say it can’t be done, but just that it should be done very carefully.
Anyway, all that to say, when choosing a project, make sure it matches your intrinsic strengths and motivations. Research is already hard enough, work on things you like to do!
One of the most common questions I get from new students is how to choose a scientific project. Clearly a super important part of the scientific process, but one that has had a somewhat magical quality to it, as though there is some magic wand that one waves over a set of eppendorf tubes to turn them into a preprint that everyone wants to read. Of course, many scientists have some introspection and insight into their thought processes, and while that has largely been passed on by word of mouth, there have been some wonderful recent efforts to describe project ideation (creativity), selection, and execution (see work from Itai Yanai/Martin Lorsch, Uri Alon, Michael Fischbach, and probably several others I’m missing with apologies).
But I feel like a lot of this discussion has missed one critical feature: you. As in you, the one actually doing the project. Everyone has different strengths and weaknesses as a scientist, or more relevantly, passions and aversions. In my experience, which I’m sure many have shared, it’s the match between the project and the scientist that matters far more than the project on its own.
Why does it matter so much? Here’s my theory. Academic research is a highly unstructured work environment. It is hard to quantify, on a daily, weekly, or even monthly basis, exactly what constitutes “progress”. As such, it relies very strongly on intrinsic motivation. As in, you really have to want to do something in order to put in the sustained effort required to actually do it, because it is very difficult to quantify progress from the outside to help force you to do things you don’t want to do. It is possible to force yourself to do things you don’t want in the short term, but if you are not fundamentally excited to do something, it is very hard to keep yourself motivated to do it in the medium-to-long term.
What does this mean in practice? I think it’s easier to see how it plays out by looking at common failure modes in person-project matching. One common thing I’ve seen is sometimes people feel like they need to build experimental skills even though they are fundamentally more interested in computational work, so they want to work on a project that has a significant experimental component. Then what happens is some version of the following: “I could do this experiment today, but it’s Thursday at 4pm. I’ll do it tomorrow. Oh wait, it’s Friday, now I should probably wait until Monday” and next thing you know a month goes by and the experiment still hasn’t gotten done. Sometimes, if you take the same person and give them a dataset, they’re like “I just need this analysis to finish running by 4pm, then I can run the next step, oh wouldn’t it be cool if XYZ were true, hold on let me try this…”. It’s hard to ascribe these delays or accelerations to any one particular decision, but in aggregate, they have an enormous compounding effect. Same sort of thing the other way around.
By the way, this doesn’t mean that you shouldn’t try things, especially early on. I worked in a lab for a summer after my first year of math grad school basically as an exercise in getting some exposure to experimental work, even though I thought I’d never EVER do it for my actual thesis work. Turns out I had a true passion for experiments. Been trying to lean into that ever since! But you have to continuously evaluate and be brutally honest with yourself about whether you’re doing what you’re doing because you really like it or because you think you should like it. I’ve found graduate students often get caught in the trap of working on what they think they should like instead of what they actually like.
This same reasoning affects choice of advisor, both graduate and postdoctoral, especially the latter. Pick an advisor who can help you build on your strengths, and not someone who specializes in your weaknesses. This is not to say that you can’t have complementary skills—especially for postdocs, it is often very fruitful to combine your skills from your PhD with a set of techniques in the postdoc lab. But if you join a lab where the advisor is a skilled computationalist but you want to do some cutting edge experiments, it must be done with a lot of care. You want to be sure the rest of the environment is strong, because it will be difficult for your advisor to guide you to innovate at the edge of the field given their own strengths and weaknesses. Not to say it can’t be done, but just that it should be done very carefully.
Anyway, all that to say, when choosing a project, make sure it matches your intrinsic strengths and motivations. Research is already hard enough, work on things you like to do!
Monday, February 5, 2024
Pre-registration in molecular biology
A few years back, perhaps in pre-pandy times, I was on a faculty development panel in which I was one of two presenters. I was of course there to present on how to use Twitter to build your brand (sigh, I’m lame), and a more senior faculty member (I think a neuroscientist) was there to talk about pre-registration in lab work. He was very kind and wise-seeming, and explained how he had been pre-registering their results in the lab for a while, and how it transformed their work.
What is pre-registration? It’s probably most familiar to you in the form of clinical studies, where there was a notorious selection bias in which results would be reported. Like, does drinking coffee cause flatulence? One would have to do a randomized controlled trial to check. But if people did, say, 100 clinical trials and only reported the ones where there was a “positive” result, then you would see 5 clinical trials with p < 0.05 showing that coffee causes flatulence, and none of the contradictory results. So now you have to pre-register a trial, meaning that you have to say, I am going to do this trial with this power and what not, and then you are obligated to report the outcome, no matter what the outcome is. A great idea!
But here was someone advocating for pre-registration much closer to home, in our day to day lab work. I remembering being vehemently and vocally opposed. Sure, clinical trials are one thing, with a clearly stated hypothesis and major resources devoted to a single experiment. But in my line of work, where we are constantly trying new experiments and checking out new avenues of work, where there are tons of false leads and new directions? How could that possibly work without gumming up the works in needless bureaucracy? I was vehemently and vocally opposed, to which the senior faculty member just patiently and calmly responded “Sure, I hear you, just think about it”.
Ever since, I keep coming back to that moment, and it has come to have a major effect on how I approach our science—and especially our reporting of it. The key take home point is: if you did an experiment to answer a question, and you don’t have any reason to exclude it based on the experiment itself, then you have to report the results. Repeat: unless there is an independent basis for the exclusion of a result, you have to report the results. Or, to put it another way: if you would have included the data if the result had come out the other way, you have to report it.
Selective reporting of data is a strange issue in molecular biology in that almost everyone agrees that it is wrong and yet the overall culture of the field leans towards selective reporting in so many ways. Here is an example from our own work. In a recent paper, we were trying to confirm the knockdown of a particular protein. We were able to show a convincing knockdown by RNA FISH, but also wanted to show that the protein levels went down. We did a bunch of westerns, but the results came out ambiguously: sometimes we saw an effect and sometimes not (there are reasons that that could be the case, but we didn't confirm those because they were very difficult). The standard thing to do here would be to not report the western results. But there was no reason to exclude the experiment other than being annoyed with the results. So, we reported it.
But again, the cultural standard in molecular biology is often not to report such ambiguous results. I saw this mindset a lot early in my career, back when RNA FISH was considered cool and people wanted our help to add some RNA FISH to their paper to spice it up. There were several times when people came to us with data in support of a, shall we say… “fanciful” hypothesis, and then we would do the RNA FISH, which would basically show the hypothesis was wrong. At which point, the would-be collaborator would beg out, saying that given the “ambiguous” nature of the RNA FISH results, “perhaps we should save the data for the next paper” (which of course never materialized). After enough of these moments, I started asking potential collaborators what stage of their paper they were at, and if they were close to the end, whether they really wanted us to do this experiment. At least one time, when faced with this choice, the person said, uhhh, let’s not!
There have also been many times when we’ve tried following up on work where we are pretty sure there has been a lot of selective reporting of positive results. Let’s just say that that is an unpleasant realization to make.
I want to emphasize that I don’t think that people are being malicious or fraudulent in their work. I think the vast majority of scientists are honest people and are not trying to do something wrong. I just think that science would benefit from having a more transparent reporting of results, because it is sometimes the data that doesn’t fit the narrative that leads to something new in the future. I also don’t necessarily think we need to formally pre-register our work, although it might be an interesting experiment to try. We should just try and shift our culture a bit towards transparent reporting. One potential challenge in doing science this way is that our stories are a lot less likely to be “perfect”. There will almost always be some bits of conflicting evidence, and given our adversarial peer review system, there is seemingly a lot of pressure to keep these conflicting results out. Or is there? We have been doing this for quite a while, and I would say that our experience has been largely fine in the sense that reviewers don’t mind as long as you are transparent about it. I say “largely” because there have definitely been cases in which reviewers point out some issue that we were transparent about and reject our paper because of it. So at least in my experience, I would say that adopting this more transparent reporting of results is not entirely without consequence. All I can say is that if we do decide to make this cultural shift, we also have to be more tolerant of imperfections in the “story” when we put our reviewer hats on.
By the way, I think a lot of people tend to think of selective reporting as a problem of experimental science. Not at all the case! Same goes for every analysis of e.g. some large scale dataset: if you checked for some signal in the data, you have to report the result, regardless of whether the result came out the way you wanted. It’s actually if anything even more of an issue in computational work in some ways, where many hypotheses can be tested with the same data in (relatively) rapid fashion.
There is also a bit of a gray area in terms of what to do about false leads. Sometimes, you have an idea that goes in a new direction that has nothing to do with the story of the paper. I don’t know what to do in this case. Certainly, science would be in some ways better for having these results out there, since there was probably (hopefully?) some basis for the experiment or analysis in the first place. But it may just serve to distract from the main thread of the paper, making it harder to follow. I don’t know how best to balance these competing and important principles, but I think it’s an important discussion for us to have.
I’m very curious how people will respond to this discussion. Ultimately, there is no form or checklist that can solve the issues we have in science. Pre-registration sounds like a bureaucratic solution, but in the end, it’s just a call for careful, honest thought about the work we do. I’m sure some people reading this will have a strongly negative reaction, much like I did at first. All I’m saying is “Sure, I hear you, just think about it.” 🙂
What is pre-registration? It’s probably most familiar to you in the form of clinical studies, where there was a notorious selection bias in which results would be reported. Like, does drinking coffee cause flatulence? One would have to do a randomized controlled trial to check. But if people did, say, 100 clinical trials and only reported the ones where there was a “positive” result, then you would see 5 clinical trials with p < 0.05 showing that coffee causes flatulence, and none of the contradictory results. So now you have to pre-register a trial, meaning that you have to say, I am going to do this trial with this power and what not, and then you are obligated to report the outcome, no matter what the outcome is. A great idea!
But here was someone advocating for pre-registration much closer to home, in our day to day lab work. I remembering being vehemently and vocally opposed. Sure, clinical trials are one thing, with a clearly stated hypothesis and major resources devoted to a single experiment. But in my line of work, where we are constantly trying new experiments and checking out new avenues of work, where there are tons of false leads and new directions? How could that possibly work without gumming up the works in needless bureaucracy? I was vehemently and vocally opposed, to which the senior faculty member just patiently and calmly responded “Sure, I hear you, just think about it”.
Ever since, I keep coming back to that moment, and it has come to have a major effect on how I approach our science—and especially our reporting of it. The key take home point is: if you did an experiment to answer a question, and you don’t have any reason to exclude it based on the experiment itself, then you have to report the results. Repeat: unless there is an independent basis for the exclusion of a result, you have to report the results. Or, to put it another way: if you would have included the data if the result had come out the other way, you have to report it.
Selective reporting of data is a strange issue in molecular biology in that almost everyone agrees that it is wrong and yet the overall culture of the field leans towards selective reporting in so many ways. Here is an example from our own work. In a recent paper, we were trying to confirm the knockdown of a particular protein. We were able to show a convincing knockdown by RNA FISH, but also wanted to show that the protein levels went down. We did a bunch of westerns, but the results came out ambiguously: sometimes we saw an effect and sometimes not (there are reasons that that could be the case, but we didn't confirm those because they were very difficult). The standard thing to do here would be to not report the western results. But there was no reason to exclude the experiment other than being annoyed with the results. So, we reported it.
But again, the cultural standard in molecular biology is often not to report such ambiguous results. I saw this mindset a lot early in my career, back when RNA FISH was considered cool and people wanted our help to add some RNA FISH to their paper to spice it up. There were several times when people came to us with data in support of a, shall we say… “fanciful” hypothesis, and then we would do the RNA FISH, which would basically show the hypothesis was wrong. At which point, the would-be collaborator would beg out, saying that given the “ambiguous” nature of the RNA FISH results, “perhaps we should save the data for the next paper” (which of course never materialized). After enough of these moments, I started asking potential collaborators what stage of their paper they were at, and if they were close to the end, whether they really wanted us to do this experiment. At least one time, when faced with this choice, the person said, uhhh, let’s not!
There have also been many times when we’ve tried following up on work where we are pretty sure there has been a lot of selective reporting of positive results. Let’s just say that that is an unpleasant realization to make.
I want to emphasize that I don’t think that people are being malicious or fraudulent in their work. I think the vast majority of scientists are honest people and are not trying to do something wrong. I just think that science would benefit from having a more transparent reporting of results, because it is sometimes the data that doesn’t fit the narrative that leads to something new in the future. I also don’t necessarily think we need to formally pre-register our work, although it might be an interesting experiment to try. We should just try and shift our culture a bit towards transparent reporting. One potential challenge in doing science this way is that our stories are a lot less likely to be “perfect”. There will almost always be some bits of conflicting evidence, and given our adversarial peer review system, there is seemingly a lot of pressure to keep these conflicting results out. Or is there? We have been doing this for quite a while, and I would say that our experience has been largely fine in the sense that reviewers don’t mind as long as you are transparent about it. I say “largely” because there have definitely been cases in which reviewers point out some issue that we were transparent about and reject our paper because of it. So at least in my experience, I would say that adopting this more transparent reporting of results is not entirely without consequence. All I can say is that if we do decide to make this cultural shift, we also have to be more tolerant of imperfections in the “story” when we put our reviewer hats on.
By the way, I think a lot of people tend to think of selective reporting as a problem of experimental science. Not at all the case! Same goes for every analysis of e.g. some large scale dataset: if you checked for some signal in the data, you have to report the result, regardless of whether the result came out the way you wanted. It’s actually if anything even more of an issue in computational work in some ways, where many hypotheses can be tested with the same data in (relatively) rapid fashion.
There is also a bit of a gray area in terms of what to do about false leads. Sometimes, you have an idea that goes in a new direction that has nothing to do with the story of the paper. I don’t know what to do in this case. Certainly, science would be in some ways better for having these results out there, since there was probably (hopefully?) some basis for the experiment or analysis in the first place. But it may just serve to distract from the main thread of the paper, making it harder to follow. I don’t know how best to balance these competing and important principles, but I think it’s an important discussion for us to have.
I’m very curious how people will respond to this discussion. Ultimately, there is no form or checklist that can solve the issues we have in science. Pre-registration sounds like a bureaucratic solution, but in the end, it’s just a call for careful, honest thought about the work we do. I’m sure some people reading this will have a strongly negative reaction, much like I did at first. All I’m saying is “Sure, I hear you, just think about it.” 🙂
Friday, July 31, 2020
Alternative hypotheses and the Gautham Transform
As I have mentioned several times, having Gautham in the lab really changed how I think about science. In particular, I learned a lot about how to take a more critical approach to science. I think this has made me a far better and more rigorous scientist, and I want to impart those lessons to all members of the lab.
The most important thing I learned from Gautham was to consider alternative hypotheses. I know this sounds like duh, that’s what I learn in my RCR meetings, “expected outcomes and potential pitfalls” sections of grants, and boring classes on how to do science, but I think that’s because we so rarely see how powerful it is in practice. I think it was one of Gautham’s favorite pastimes, and really exemplified his scientific aesthetic (indeed, he was very well known for demonstrating some alternative hypotheses for carrier multiplication, I believe). There were many, many times Gautham proposed alternative hypotheses in our lab, and it was always illuminating. Indeed, one of the main points of his second paper from the lab was about how one could explain “fluctuations between states” by simple population dynamics without any state switching—a whole paper’s worth of alternative hypothesis!
Why do we generally fail to consider alternative hypotheses? One reason is that it’s scary and not fun. Generally, the hypothesis you want to consider is the option that is the fun one. It is scary to contemplate the idea that something fun might turn out to be something boring. (Gautham and I used to joke that the “Gautham Transform” was taking something seemingly interesting and showing that it was actually boring.) The truth of it, though, is that most things are boring. Sure, in biology, there are a lot more surprises than in, say, physics, but there are still far fewer interesting things than are generally claimed. I think that we would all do better to come in with a stronger prior belief that most findings actually have a boring explanation, and a critical implementation of that belief is to propose alternative hypotheses. Keep in mind also that when we are trained, we typically are presented with a list of facts with no alternatives. This manner of pedagogy leaves most of us with very little appreciation for all the wrong turns that comprise science as it’s being made as opposed to the little diagrams in the textbooks.
The other reason we fail to consider alternatives is that it’s a lot of work. It’s always going to be harder to spend as much time actively thinking of ways to show that your pet theory is incorrect, and so in my experience it’s usually more work to come up with plausible alternative hypotheses. Usually, this difficulty manifests as a proclamation of “there’s just no other way it could be!” Thing is… there’s ALWAYS an alternative hypothesis. All models are wrong. You may get to a point where you just get tired, or the alternatives seem too outlandish, but there’s always another alternative to exclude. I remember as we were wrapping up our transcriptional-scaling-with-cell-size manuscript, we got this cool result suggesting that transcription was cut in half upon DNA replication (decrease in burst frequency). I was really into this idea, and Gautham was like, that’s really weird, there must be some other explanation. I was like, I can’t think of one, and I remember him saying “Well, it’s hard, but there has to be something, what you’re proposing is really weird”. So… I spent a couple days thinking about it, and then, voila, an alternative! (The alternative was a global decrease in transcription in S-phase, which Olivia eliminated with a clever experiment measuring transcription from a late-replicating gene.) Point is, it’s hard but necessary work.
(Note: I’m wondering about ways to actively encourage people to consider alternatives on a more regular basis. One suggestion was to stop, say, group meeting somewhere in the middle and just explicitly ask everyone to think of alternatives for a few minutes, then check in. Another option (HT Ben Emert) is to have a lab buddy who’s job is to work with you to challenge hypotheses. Anybody have other thoughts?)
So when do you stop making alternatives? I think that’s largely a matter of taste. At some point, you have to stand by a model you propose, exclude as many plausible alternatives as you can, and then acknowledge that there are other possible explanations for what you see that you just didn’t think of. Progress continues, excluding one alternative at a time…
The most important thing I learned from Gautham was to consider alternative hypotheses. I know this sounds like duh, that’s what I learn in my RCR meetings, “expected outcomes and potential pitfalls” sections of grants, and boring classes on how to do science, but I think that’s because we so rarely see how powerful it is in practice. I think it was one of Gautham’s favorite pastimes, and really exemplified his scientific aesthetic (indeed, he was very well known for demonstrating some alternative hypotheses for carrier multiplication, I believe). There were many, many times Gautham proposed alternative hypotheses in our lab, and it was always illuminating. Indeed, one of the main points of his second paper from the lab was about how one could explain “fluctuations between states” by simple population dynamics without any state switching—a whole paper’s worth of alternative hypothesis!
Why do we generally fail to consider alternative hypotheses? One reason is that it’s scary and not fun. Generally, the hypothesis you want to consider is the option that is the fun one. It is scary to contemplate the idea that something fun might turn out to be something boring. (Gautham and I used to joke that the “Gautham Transform” was taking something seemingly interesting and showing that it was actually boring.) The truth of it, though, is that most things are boring. Sure, in biology, there are a lot more surprises than in, say, physics, but there are still far fewer interesting things than are generally claimed. I think that we would all do better to come in with a stronger prior belief that most findings actually have a boring explanation, and a critical implementation of that belief is to propose alternative hypotheses. Keep in mind also that when we are trained, we typically are presented with a list of facts with no alternatives. This manner of pedagogy leaves most of us with very little appreciation for all the wrong turns that comprise science as it’s being made as opposed to the little diagrams in the textbooks.
The other reason we fail to consider alternatives is that it’s a lot of work. It’s always going to be harder to spend as much time actively thinking of ways to show that your pet theory is incorrect, and so in my experience it’s usually more work to come up with plausible alternative hypotheses. Usually, this difficulty manifests as a proclamation of “there’s just no other way it could be!” Thing is… there’s ALWAYS an alternative hypothesis. All models are wrong. You may get to a point where you just get tired, or the alternatives seem too outlandish, but there’s always another alternative to exclude. I remember as we were wrapping up our transcriptional-scaling-with-cell-size manuscript, we got this cool result suggesting that transcription was cut in half upon DNA replication (decrease in burst frequency). I was really into this idea, and Gautham was like, that’s really weird, there must be some other explanation. I was like, I can’t think of one, and I remember him saying “Well, it’s hard, but there has to be something, what you’re proposing is really weird”. So… I spent a couple days thinking about it, and then, voila, an alternative! (The alternative was a global decrease in transcription in S-phase, which Olivia eliminated with a clever experiment measuring transcription from a late-replicating gene.) Point is, it’s hard but necessary work.
(Note: I’m wondering about ways to actively encourage people to consider alternatives on a more regular basis. One suggestion was to stop, say, group meeting somewhere in the middle and just explicitly ask everyone to think of alternatives for a few minutes, then check in. Another option (HT Ben Emert) is to have a lab buddy who’s job is to work with you to challenge hypotheses. Anybody have other thoughts?)
So when do you stop making alternatives? I think that’s largely a matter of taste. At some point, you have to stand by a model you propose, exclude as many plausible alternatives as you can, and then acknowledge that there are other possible explanations for what you see that you just didn’t think of. Progress continues, excluding one alternative at a time…
Sunday, August 4, 2019
I need a coach
I’ve been ruminating over the course of the last several years on a conversation I had with Rob Phillips about coaches. He was saying (and hopefully he will forgive me if I’m mischaracterizing this) that he has had people serve the role of coach in his life before, and that that really helped push him to do better. It’s something I keep coming back to over and over, especially as I get further along in my career.
In processing what Rob was saying, one of the first questions that needed answering is exactly what is a coach? I think most of us think about formal training interactions (i.e., students, postdocs) when we think of coaching in science, and I think this ends up conflating two actually rather disparate things, which are mentoring and coaching. At least for me, mentorship is about wisdom that I have accumulated about decision making that I can hopefully pass on to others. These can be things like “Hmm, I think that experiment is unlikely to be informative” or “That area of research is pretty promising” or “I don’t think that will matter much for a job application, I would spend your time on this instead”. A coach, on the other hand, is someone who will help push you to focus and implement strategies for things you already know, but are having trouble doing. Like “I think we can get this experiment done faster” or “This code could be more cleanly written” or “This experiment is sloppy, let’s clean it up”. Basically, a mentor gives advice on what to do, a coach gives advice on how to actually do it.
Why does this decoupling matter, especially later in your career? When in a formal training situation, you will often get both of these from the same people—the same person, say, guiding your research project is the same person pushing you to get things done right. But after a few years in a faculty position, the N starts to get pretty small, and as such I think the value of mentorship per se diminishes significantly; basically, everybody gives you a bunch of conflicting advice on what to do in any given situation, which is frankly mostly just a collection of well-meaning but at best mildly useful anecdotes. But while the utility of mentorship decreases (or perhaps the availability of high quality mentorship) decreases, I have found that I still have a need for someone to hold me accountable, to help me implement the wisdom that I have accumulated but am sometimes too lazy or scared to put into practice. Like, someone to say “hey, watch a recording of your lecture finally and implement the changes” or “push yourself to think more mechanistically, your ideas are weak” or “that writing is lazy, do better” or “finish that half-written blog post”. To some extent, you can get this from various people in your life, and I desperately seek those people out, but it’s increasingly hard to find the further along you are. Moreover, even if you do find someone, they may have a different set of wisdom that they would be trying to implement for you, like, coaching you towards what they think is good, not what you yourself think is good (“Always need a hypothesis in each specific aim” whereas maybe you’ve come to the conclusion that that’s not important or whatever). If you have gotten to the point where you’ve developed your own set of models of what matters or doesn’t in the world, then you somehow need to be able to coach yourself in order to achieve those goals.
Is it possible to self-coach? I think so, but I’ve always struggled to figure out how. I guess the first step is to think about what makes a good coach. To me, the role of a good coach is to devise a concrete plan (often with some sort of measurable outcome) that promotes a desired change in default behavior. For example, when working with people in the lab in a coaching capacity, one thing I’ve tried to do is to propose concrete goals to try and help overcome barriers. If someone could be participating more in group meeting and seminars, I’ll say “try to ask at least 3 questions at group meeting and one at every seminar” and that does seem to help. Or I’ll push someone to make their figures, or write down their experiment along with results and conclusions. Or make a list of things to do in a day and then search for one more thing to add. Setting these sorts of rules can help provide the structure to achieve these goals and model new behaviors.
How do you implement these coaching strategies for yourself? I think there are a few steps, the first of which are relatively easy. Initially, the issue is to identify the issue, which is actually usually fairly clear: “I want to reduce time spent on email”, “I want to write clean code”, “I want to construct a set of alternative hypotheses every time I come up with some fun new idea”, “Push myself to really think in a model-based fashion”. Next, is reduction to a concrete set of goals, which is also usually pretty easy: “Read every email only once and batch process them for a set period of time” or “write software that follows XYZ design pattern” or “write down alternative hypotheses”. The biggest struggle is accountability, which is where having a coach would be good. How do I enforce the rules when I’m the only one following them?
I’m not really sure, but one thing that works for me (which is perhaps quite obvious) is to rely on something external for accountability. For example, I am always looking for ways to improve my talks, and value being able to do a good job. However, it was hard to get feedback, and even when I did, I often didn’t follow through to implement said feedback. So I did this thing where I show the audience a QR code which leads them to a form for feedback. Often, they pointed out things I didn’t realize were unclear, which was of course helpful. But what was also helpful was when they pointed out things that I already knew were unclear, but had been lazy about fixing. This provided me with a bit of motivation to finally fix the issue, and I think it’s improved things overall. Another externalization strategy I’ve tried is to imagine that I’m trying to model behavior for someone else. Example: I was writing some software a while back for the lab, and there were times where I could have done something in the quick, lazy, and wrong way, rather than in the right way. What helped motivate me to do it right was to say to myself, “Hey, people in the lab are going to look at this software as an example of how to do things, and I need to make sure they learn the right things, so do it right, dummy”.
Some things are really hard to externalize, like making sure you stress test your ideas with alternative hypotheses and designing the experiments that will rigorously test them. One form of externalization that works for me is to imagine former lab members who were really smart and critical and just imagine them saying to me “but what about…”. Just imagining what they might say somehow helps me push myself to think a bit harder.
Any thoughts on other ways to hold yourself accountable when nobody else is looking?
In processing what Rob was saying, one of the first questions that needed answering is exactly what is a coach? I think most of us think about formal training interactions (i.e., students, postdocs) when we think of coaching in science, and I think this ends up conflating two actually rather disparate things, which are mentoring and coaching. At least for me, mentorship is about wisdom that I have accumulated about decision making that I can hopefully pass on to others. These can be things like “Hmm, I think that experiment is unlikely to be informative” or “That area of research is pretty promising” or “I don’t think that will matter much for a job application, I would spend your time on this instead”. A coach, on the other hand, is someone who will help push you to focus and implement strategies for things you already know, but are having trouble doing. Like “I think we can get this experiment done faster” or “This code could be more cleanly written” or “This experiment is sloppy, let’s clean it up”. Basically, a mentor gives advice on what to do, a coach gives advice on how to actually do it.
Why does this decoupling matter, especially later in your career? When in a formal training situation, you will often get both of these from the same people—the same person, say, guiding your research project is the same person pushing you to get things done right. But after a few years in a faculty position, the N starts to get pretty small, and as such I think the value of mentorship per se diminishes significantly; basically, everybody gives you a bunch of conflicting advice on what to do in any given situation, which is frankly mostly just a collection of well-meaning but at best mildly useful anecdotes. But while the utility of mentorship decreases (or perhaps the availability of high quality mentorship) decreases, I have found that I still have a need for someone to hold me accountable, to help me implement the wisdom that I have accumulated but am sometimes too lazy or scared to put into practice. Like, someone to say “hey, watch a recording of your lecture finally and implement the changes” or “push yourself to think more mechanistically, your ideas are weak” or “that writing is lazy, do better” or “finish that half-written blog post”. To some extent, you can get this from various people in your life, and I desperately seek those people out, but it’s increasingly hard to find the further along you are. Moreover, even if you do find someone, they may have a different set of wisdom that they would be trying to implement for you, like, coaching you towards what they think is good, not what you yourself think is good (“Always need a hypothesis in each specific aim” whereas maybe you’ve come to the conclusion that that’s not important or whatever). If you have gotten to the point where you’ve developed your own set of models of what matters or doesn’t in the world, then you somehow need to be able to coach yourself in order to achieve those goals.
Is it possible to self-coach? I think so, but I’ve always struggled to figure out how. I guess the first step is to think about what makes a good coach. To me, the role of a good coach is to devise a concrete plan (often with some sort of measurable outcome) that promotes a desired change in default behavior. For example, when working with people in the lab in a coaching capacity, one thing I’ve tried to do is to propose concrete goals to try and help overcome barriers. If someone could be participating more in group meeting and seminars, I’ll say “try to ask at least 3 questions at group meeting and one at every seminar” and that does seem to help. Or I’ll push someone to make their figures, or write down their experiment along with results and conclusions. Or make a list of things to do in a day and then search for one more thing to add. Setting these sorts of rules can help provide the structure to achieve these goals and model new behaviors.
How do you implement these coaching strategies for yourself? I think there are a few steps, the first of which are relatively easy. Initially, the issue is to identify the issue, which is actually usually fairly clear: “I want to reduce time spent on email”, “I want to write clean code”, “I want to construct a set of alternative hypotheses every time I come up with some fun new idea”, “Push myself to really think in a model-based fashion”. Next, is reduction to a concrete set of goals, which is also usually pretty easy: “Read every email only once and batch process them for a set period of time” or “write software that follows XYZ design pattern” or “write down alternative hypotheses”. The biggest struggle is accountability, which is where having a coach would be good. How do I enforce the rules when I’m the only one following them?
I’m not really sure, but one thing that works for me (which is perhaps quite obvious) is to rely on something external for accountability. For example, I am always looking for ways to improve my talks, and value being able to do a good job. However, it was hard to get feedback, and even when I did, I often didn’t follow through to implement said feedback. So I did this thing where I show the audience a QR code which leads them to a form for feedback. Often, they pointed out things I didn’t realize were unclear, which was of course helpful. But what was also helpful was when they pointed out things that I already knew were unclear, but had been lazy about fixing. This provided me with a bit of motivation to finally fix the issue, and I think it’s improved things overall. Another externalization strategy I’ve tried is to imagine that I’m trying to model behavior for someone else. Example: I was writing some software a while back for the lab, and there were times where I could have done something in the quick, lazy, and wrong way, rather than in the right way. What helped motivate me to do it right was to say to myself, “Hey, people in the lab are going to look at this software as an example of how to do things, and I need to make sure they learn the right things, so do it right, dummy”.
Some things are really hard to externalize, like making sure you stress test your ideas with alternative hypotheses and designing the experiments that will rigorously test them. One form of externalization that works for me is to imagine former lab members who were really smart and critical and just imagine them saying to me “but what about…”. Just imagining what they might say somehow helps me push myself to think a bit harder.
Any thoughts on other ways to hold yourself accountable when nobody else is looking?
Wednesday, August 8, 2018
On mechanism and systems biology
(Latest in a slowly unfolding series of blog posts from the Paros conference.)
Related reading:

Mechanism. The word fills many of us with dread: “Not enough mechanism.” “Not particularly mechanistic.” "What's the mechanism?" So then what exactly do we mean by mechanism? I don’t think it’s an idle question—rather, I think it gets down to the very essence of what we think science means. And I think there are some practical consequences on everything from how we report results to the questions we may choose to study (and consequently to how we evaluate science). So I’ll try and organize this post around a few concrete proposals.
To start: I think the definition I’ve settled on for mechanism is “a model for how something works”.
I think it’s interesting to think about how the term mechanism has evolved in our field from something that really was mechanism once upon a time into something that is really not mechanism. In the old days, mechanism meant figuring out e.g. what an enzyme did and how it worked, perhaps in conjunction with other enzymes. Things like DNA polymerase and ATP synthase. The power of the hard mechanistic knowledge of this era is hard to overstate.
What can we learn about the power of mechanism/models from this example?
As the author of this post argues, models/theories are “inference tickets” that allow you to make hard predictions in completely new situations without testing them. We are used to thinking of models as being written in math and making quantitative predictions, but this need not be the case. Here, the predictions of how these enzymes function has led to, amongst other things, our entire molecular biology toolkit: add this enzyme, it will phosphorylate your DNA, add this other enzyme, it will ligate that to another piece of DNA. That these enzymes perform certain functions is a “mechanism” that we used to predict what would happen if we put these molecules in a test tube together, and that largely bore out, with huge practical implications.
Mechanisms necessarily come with a layer of abstraction. Perhaps we are more used to talking about these in models, where we have a name for them: “assumptions”. Essentially, there is a point at which we say, who knows, we’re just going to say that this is the way it is, and then build our model from there. In this case, it’s that the enzyme does what we say it will. We still have quite a limited ability to take an unknown sequence of amino acids and predict what it will do, and certainly very limited ability to take a desired function and just write out the sequence to accomplish said function. We just say, okay, assume these molecules do XYZ, and then our model is that they are important for e.g. transcription, or reverse transcription, or DNA replication, or whatever.
Fast forward to today, when a lot of us are studying biological regulation, and we have a very different notion of what constitutes “mechanism”. Now, it’s like oh, I see a correlation between X and Y, the reviewer asks for “mechanism”, so you knock down X and see less Y, and that’s “mechanism”. Not to completely discount this—I mean, we’ve learned a fair amount by doing these sorts of experiments, but I think it’s a pretty clear that this is not sufficient to say that we know how it works. Rather, this is a devolution to empiricism, which is something I think we need to fix in our field.
Perhaps the most salient question is what it does it mean to know “how it works?”. I posit that mechanism is an inference that connects one bit of empiricism to another. Let’s illustrate in the case of something where we do know the mechanism/model: a lever.
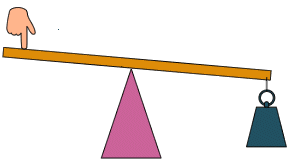
“How it works” in this context means that we need a layer of abstraction, and have some degree of inference given that layer of abstraction. Here, the question may be “how hard do I have to push to lift the weight?”. Do we need to know that the matter is composed of quarks to make this prediction, or how hard the lever itself is? No. Do we need to know how the string works? No. We just assume the weight pulls down on the string and whatever it’s made of is irrelevant because we know these to be empirically the case. We are going to assume that the only things that matter are the locations of the weight, the fulcrum, and my finger, as well as the weight of the, uhh, weight and how hard I push. This is the layer of abstraction the model is based on. The model we use is that of force balance, and we can use that to predict exactly how hard to push given these distances and weights.
How would a modern data scientist approach this problem? Probably take like 10,000 levers and discover Archimedes Law of the Lever by making a lot of plots in R. Who knows, maybe this is basically how Archimedes figured it out in the first place. It is perhaps often possible to figure out a relationship empirically, and even make some predictions. But that’s not what we (or at least I) consider a mechanism. I think there has to be something beyond pure empiricism, often linking very disparate scales or processes, sometimes in ways that are simply impossible to investigate empirically. In this case, we can use the concepts of force to figure out how things might work with, say, multiple weights, or systems of weights on levers, or even things that don’t look like levers at all. Wow!
Related reading:
- Musings on Mechanism, Rob Phillips, https://www.ncbi.nlm.nih.gov/pubmed/28963318
- Excellent blog post on "Theoretical Amnesia" http://osc.centerforopenscience.org/2013/11/20/theoretical-amnesia/)
Mechanism. The word fills many of us with dread: “Not enough mechanism.” “Not particularly mechanistic.” "What's the mechanism?" So then what exactly do we mean by mechanism? I don’t think it’s an idle question—rather, I think it gets down to the very essence of what we think science means. And I think there are some practical consequences on everything from how we report results to the questions we may choose to study (and consequently to how we evaluate science). So I’ll try and organize this post around a few concrete proposals.
To start: I think the definition I’ve settled on for mechanism is “a model for how something works”.
I think it’s interesting to think about how the term mechanism has evolved in our field from something that really was mechanism once upon a time into something that is really not mechanism. In the old days, mechanism meant figuring out e.g. what an enzyme did and how it worked, perhaps in conjunction with other enzymes. Things like DNA polymerase and ATP synthase. The power of the hard mechanistic knowledge of this era is hard to overstate.
What can we learn about the power of mechanism/models from this example?
As the author of this post argues, models/theories are “inference tickets” that allow you to make hard predictions in completely new situations without testing them. We are used to thinking of models as being written in math and making quantitative predictions, but this need not be the case. Here, the predictions of how these enzymes function has led to, amongst other things, our entire molecular biology toolkit: add this enzyme, it will phosphorylate your DNA, add this other enzyme, it will ligate that to another piece of DNA. That these enzymes perform certain functions is a “mechanism” that we used to predict what would happen if we put these molecules in a test tube together, and that largely bore out, with huge practical implications.
Mechanisms necessarily come with a layer of abstraction. Perhaps we are more used to talking about these in models, where we have a name for them: “assumptions”. Essentially, there is a point at which we say, who knows, we’re just going to say that this is the way it is, and then build our model from there. In this case, it’s that the enzyme does what we say it will. We still have quite a limited ability to take an unknown sequence of amino acids and predict what it will do, and certainly very limited ability to take a desired function and just write out the sequence to accomplish said function. We just say, okay, assume these molecules do XYZ, and then our model is that they are important for e.g. transcription, or reverse transcription, or DNA replication, or whatever.
Fast forward to today, when a lot of us are studying biological regulation, and we have a very different notion of what constitutes “mechanism”. Now, it’s like oh, I see a correlation between X and Y, the reviewer asks for “mechanism”, so you knock down X and see less Y, and that’s “mechanism”. Not to completely discount this—I mean, we’ve learned a fair amount by doing these sorts of experiments, but I think it’s a pretty clear that this is not sufficient to say that we know how it works. Rather, this is a devolution to empiricism, which is something I think we need to fix in our field.
Perhaps the most salient question is what it does it mean to know “how it works?”. I posit that mechanism is an inference that connects one bit of empiricism to another. Let’s illustrate in the case of something where we do know the mechanism/model: a lever.
“How it works” in this context means that we need a layer of abstraction, and have some degree of inference given that layer of abstraction. Here, the question may be “how hard do I have to push to lift the weight?”. Do we need to know that the matter is composed of quarks to make this prediction, or how hard the lever itself is? No. Do we need to know how the string works? No. We just assume the weight pulls down on the string and whatever it’s made of is irrelevant because we know these to be empirically the case. We are going to assume that the only things that matter are the locations of the weight, the fulcrum, and my finger, as well as the weight of the, uhh, weight and how hard I push. This is the layer of abstraction the model is based on. The model we use is that of force balance, and we can use that to predict exactly how hard to push given these distances and weights.
How would a modern data scientist approach this problem? Probably take like 10,000 levers and discover Archimedes Law of the Lever by making a lot of plots in R. Who knows, maybe this is basically how Archimedes figured it out in the first place. It is perhaps often possible to figure out a relationship empirically, and even make some predictions. But that’s not what we (or at least I) consider a mechanism. I think there has to be something beyond pure empiricism, often linking very disparate scales or processes, sometimes in ways that are simply impossible to investigate empirically. In this case, we can use the concepts of force to figure out how things might work with, say, multiple weights, or systems of weights on levers, or even things that don’t look like levers at all. Wow!
Okay, so back to regulatory biology. I think one issue that we suffer from is that what we call mechanism has moved away from true “how it works” models and settled into what is really empiricism, sort of without us noticing it. Consider, for instance, development. People will say, oh, this transcription factor controls intestinal development. Why do they say that? Well, knock it out and there’s no intestine. Put it somewhere else and now you get extra intestine. Okay, but that’s not how it works. It’s empirical. How can you spot empiricism? A good sign is excessive obsession with statistics: effect sizes and p-values are often a good sign that you didn’t really figure out how it works. Another sign is that we aren’t really able to apply what we learned outside of the original context. If I gave you a DNA typewriter and said, okay, make an intestine, you would have no idea how to do it, right? We can make more intestine in the original context, but the domain of applicability is pretty limited.
Personally, I think that these difficulties arise partially because of our tools, but mostly because I think we are still focused on the wrong layers of abstraction. Probably the most common current layers of abstraction are those of genes/molecules, cells, and organisms. Our most powerful models/mechanisms to date are the ones where we could draw straight lines connecting these up. Like, mutate this gene, make these cells look funny, now this person has this disease. However, I think these straight lines are more the exception than the norm. Mostly, I think these mappings are highly convoluted in interwoven systems, making it very hard to make predictions based on empiricism alone (future blog post coming on Omnigenic Model to discuss this further).
Which leads me to a proposal: let’s start thinking about other layers of abstraction. I think that the successes of the genes/molecules -> cells paradigm has led to a certain ossification of thought centered around thinking of genes and molecules and cells as being the right layers of abstraction. But maybe genes and cells are not such fundamental units as we think they are. In the context of multicellular organisms, perhaps cells themselves are passive players, and rather it is communities of cells that are the fundamental unit. Organoids could be a good example of this, dunno. Also, it is becoming clear that genetics has some pretty serious limits in terms of determining mechanism in the sense I’ve defined. Is there some other layer involving perhaps groups of genes? Sorry, not a particularly inspired idea, but whatever, something like that maybe. Part of thinking this way also means that we have to reconsider how we evaluate science. As Rob pointed out, we have gotten so used to equating “mechanism” to “molecules and their effects on cells” that we have become both closed minded to other potential types of mechanism while also deceiving ourselves into allowing empiricism to pose as mechanism under the guise of statistics. We just have to be open to new abstractions and not hold everyone to the "What's the molecule?" standard.
Of course, underlying this is an open question: do such layers of abstraction that allow mechanism in the true sense exist? Complexity seems to be everywhere in biology, and my reaction so far has been to just throw up my hands up and say “it’s complicated!”. But (and this is another lesson learned from Rob), that’s not an excuse—we have to at least try. And I do think we can find some mechanistic wormholes through the seemingly infinite space of empiricism that we are currently mired in.
Regardless of what layers of abstraction we choose, however, I think that it is clear that a common feature of these future models will be that they are multifactorial, meaning that they will simultaneously incorporate the interactions of multiple molecules or cells or whatever the units we choose are. How do we deal with multiple interactions? I’m not alone in thinking that our models need to be quantitative, which as noted in my first post, is an idea that’s been around for some time now. However, I think that a fair charge is that in the early days of this field, our quantitative models were pretty much window dressing. I think (again a point that I’ve finally absorbed from Rob) that we have to start setting (and reporting) quantitative goals. We can’t pick and choose how our science is quantitative. If we have some pretty model for something, we better do the hard work to get the parameters we need, make hard quantitative predictions, and then stick to them. And if we don’t quantitatively get what we predict, we have to admit we were wrong. Not partly right, which is what we do now. Here’s the current playbook for a SysBio paper: quantitatively measure some phenomenon, make a nice model, predict that removal of factor X should send factor Y up by 4x, measure that it went up 2x, and put a bow on it and call it a day. I think we just have to admit that this is not good enough. This “pick and choose” mix of quantitative and qualitative analyses is hugely damaging because it makes it impossible to build upon these models. The problem is that qualitative reporting in, say, abstracts leads to people seeing “X affects Y” and “Y affects Z” and concluding “thus, X affects Z” even though the effects for X on Y and Y on Z may be small enough to make this conclusion pretty tenuous.
So I have a couple proposals. One is that in abstracts, every statement should include some sort of measure of the percentage of effect explained by the putative mechanism. I.e., you can’t just say “X affects Y”. You have to say something like “X explains 40% of the change in Y”. I know, this is hard to do, and requires thought about exactly what “explains” means. But yeah, science is hard work. Until we are honest about this, we’re always going to be “quantitative” biologists instead of true quantitative biologists.
Also, as a related grand challenge, I think it would be cool to try and be able to explain some regulatory process in biology out to 99.9%. As in, okay, we really now understand in some pretty solid way how something works. Like, we actually have mechanism in the true sense. You can argue that this number is arbitrary, and it is, but I think it could function well as an aspirational goal.
Any discussion of empiricism vs. theory will touch on the question of science vs. engineering. I would argue that—because we’re in an age of empiricism—most of what we’re doing in biology right now is probably best called engineering. Trying to make cells divide faster or turn into this cell or kill that other cell. And it’s true that look, whatever, if I can fix your heart, who cares if I have a theory of heart? One of my favorite stories along these lines is the story of how fracking was discovered, which was purely by accident (see Planet Money podcast): a desperate gas engineer looking to cut costs just kept cutting out an expensive chemical and seeing better yield until he just went with pure water and, voila, more gas than ever. Why? Who cares! Then again, think about how many mechanistic models went into, e.g., the design of the drills, transportation, everything else that goes into delivering energy. I think this highlights the fact that just like science and engineering are intertwined, so are mechanism and empiricism. Perhaps it’s time, though, to reconsider what we mean by mechanism to make it both more expansive and rigorous.
Personally, I think that these difficulties arise partially because of our tools, but mostly because I think we are still focused on the wrong layers of abstraction. Probably the most common current layers of abstraction are those of genes/molecules, cells, and organisms. Our most powerful models/mechanisms to date are the ones where we could draw straight lines connecting these up. Like, mutate this gene, make these cells look funny, now this person has this disease. However, I think these straight lines are more the exception than the norm. Mostly, I think these mappings are highly convoluted in interwoven systems, making it very hard to make predictions based on empiricism alone (future blog post coming on Omnigenic Model to discuss this further).
Which leads me to a proposal: let’s start thinking about other layers of abstraction. I think that the successes of the genes/molecules -> cells paradigm has led to a certain ossification of thought centered around thinking of genes and molecules and cells as being the right layers of abstraction. But maybe genes and cells are not such fundamental units as we think they are. In the context of multicellular organisms, perhaps cells themselves are passive players, and rather it is communities of cells that are the fundamental unit. Organoids could be a good example of this, dunno. Also, it is becoming clear that genetics has some pretty serious limits in terms of determining mechanism in the sense I’ve defined. Is there some other layer involving perhaps groups of genes? Sorry, not a particularly inspired idea, but whatever, something like that maybe. Part of thinking this way also means that we have to reconsider how we evaluate science. As Rob pointed out, we have gotten so used to equating “mechanism” to “molecules and their effects on cells” that we have become both closed minded to other potential types of mechanism while also deceiving ourselves into allowing empiricism to pose as mechanism under the guise of statistics. We just have to be open to new abstractions and not hold everyone to the "What's the molecule?" standard.
Of course, underlying this is an open question: do such layers of abstraction that allow mechanism in the true sense exist? Complexity seems to be everywhere in biology, and my reaction so far has been to just throw up my hands up and say “it’s complicated!”. But (and this is another lesson learned from Rob), that’s not an excuse—we have to at least try. And I do think we can find some mechanistic wormholes through the seemingly infinite space of empiricism that we are currently mired in.
Regardless of what layers of abstraction we choose, however, I think that it is clear that a common feature of these future models will be that they are multifactorial, meaning that they will simultaneously incorporate the interactions of multiple molecules or cells or whatever the units we choose are. How do we deal with multiple interactions? I’m not alone in thinking that our models need to be quantitative, which as noted in my first post, is an idea that’s been around for some time now. However, I think that a fair charge is that in the early days of this field, our quantitative models were pretty much window dressing. I think (again a point that I’ve finally absorbed from Rob) that we have to start setting (and reporting) quantitative goals. We can’t pick and choose how our science is quantitative. If we have some pretty model for something, we better do the hard work to get the parameters we need, make hard quantitative predictions, and then stick to them. And if we don’t quantitatively get what we predict, we have to admit we were wrong. Not partly right, which is what we do now. Here’s the current playbook for a SysBio paper: quantitatively measure some phenomenon, make a nice model, predict that removal of factor X should send factor Y up by 4x, measure that it went up 2x, and put a bow on it and call it a day. I think we just have to admit that this is not good enough. This “pick and choose” mix of quantitative and qualitative analyses is hugely damaging because it makes it impossible to build upon these models. The problem is that qualitative reporting in, say, abstracts leads to people seeing “X affects Y” and “Y affects Z” and concluding “thus, X affects Z” even though the effects for X on Y and Y on Z may be small enough to make this conclusion pretty tenuous.
So I have a couple proposals. One is that in abstracts, every statement should include some sort of measure of the percentage of effect explained by the putative mechanism. I.e., you can’t just say “X affects Y”. You have to say something like “X explains 40% of the change in Y”. I know, this is hard to do, and requires thought about exactly what “explains” means. But yeah, science is hard work. Until we are honest about this, we’re always going to be “quantitative” biologists instead of true quantitative biologists.
Also, as a related grand challenge, I think it would be cool to try and be able to explain some regulatory process in biology out to 99.9%. As in, okay, we really now understand in some pretty solid way how something works. Like, we actually have mechanism in the true sense. You can argue that this number is arbitrary, and it is, but I think it could function well as an aspirational goal.
Any discussion of empiricism vs. theory will touch on the question of science vs. engineering. I would argue that—because we’re in an age of empiricism—most of what we’re doing in biology right now is probably best called engineering. Trying to make cells divide faster or turn into this cell or kill that other cell. And it’s true that look, whatever, if I can fix your heart, who cares if I have a theory of heart? One of my favorite stories along these lines is the story of how fracking was discovered, which was purely by accident (see Planet Money podcast): a desperate gas engineer looking to cut costs just kept cutting out an expensive chemical and seeing better yield until he just went with pure water and, voila, more gas than ever. Why? Who cares! Then again, think about how many mechanistic models went into, e.g., the design of the drills, transportation, everything else that goes into delivering energy. I think this highlights the fact that just like science and engineering are intertwined, so are mechanism and empiricism. Perhaps it’s time, though, to reconsider what we mean by mechanism to make it both more expansive and rigorous.
Saturday, April 22, 2017
What will happen when we combine replication studies with positive-result bias?
Just read a nice blog post from Stephen Heard about replicability vs. robustness that I really agree with. Basically, the idea under discussion is how much effort we should devote to exactly repeating experiments (narrow robustness) vs. the more standard way of doing science, which is everyone does their own version to see whether the result holds more generally (broad robustness). In my particular niche of molecular biology, I think most (though definitely not all, you know who you are!) errors are those of judgement rather than technical competence/integrity, and so I think most exact replication efforts are a waste of time, an argument which many other have made as well.
In the comments, some people arguing for more narrow replication studies made the point that very little (~0%) of our current research budget is devoted to explicitly to replication. Which got me wondering: what might happen if we suddenly funded a lot of replication studies?
In particular, I worry about positive-result bias. Positive-result bias is basically the natural human desire to find something new: our expectation is X, but instead we found Y. Hooray, look, new science! Press release, please! :)
Now what happens when when we start a bunch of studies with the explicit mandate to replicate a previous study? Here, the expectation is now what was already found and so positive-result bias would bias towards a refutation. I mean, let’s face it, people want to do something interesting and new that other people care about. The cancer reproducibility project in eLife provides an interesting case study: most of the press around the publication was about how the results were “muddy”, and I definitely saw a great deal more interest in what didn’t replicate than what did.
Look, I’m not saying that scientists are so hungry for attention that most, or even more than a few, would consciously try to have a replication fail (although I do wonder about that eLife replication paper that applied what seemed to be overly stringent statistical criteria in order to say something did not replicate). All I’m saying is the same hype incentives that we complain about are clearly aligned with failed replication results, and so we should be just as critical and vigilant about them.
As for apportionment of resources towards replication, I think that setting aside the question as to whether it’s a good use of money from the scientific perspective (I, like others, would argue largely not), there’s also the question of whether it’s a good use of human resources. Having a student or postdoc work on a replication study for years during their training period is not, I think, a good use of their time, and keeps them from the more valuable training experience of actually, you know, doing their own science—let alone robbing them of the thrill of new discovery. Perhaps such studies are best left to industry, which is where I believe they already largely reside.
In the comments, some people arguing for more narrow replication studies made the point that very little (~0%) of our current research budget is devoted to explicitly to replication. Which got me wondering: what might happen if we suddenly funded a lot of replication studies?
In particular, I worry about positive-result bias. Positive-result bias is basically the natural human desire to find something new: our expectation is X, but instead we found Y. Hooray, look, new science! Press release, please! :)
Now what happens when when we start a bunch of studies with the explicit mandate to replicate a previous study? Here, the expectation is now what was already found and so positive-result bias would bias towards a refutation. I mean, let’s face it, people want to do something interesting and new that other people care about. The cancer reproducibility project in eLife provides an interesting case study: most of the press around the publication was about how the results were “muddy”, and I definitely saw a great deal more interest in what didn’t replicate than what did.
Look, I’m not saying that scientists are so hungry for attention that most, or even more than a few, would consciously try to have a replication fail (although I do wonder about that eLife replication paper that applied what seemed to be overly stringent statistical criteria in order to say something did not replicate). All I’m saying is the same hype incentives that we complain about are clearly aligned with failed replication results, and so we should be just as critical and vigilant about them.
As for apportionment of resources towards replication, I think that setting aside the question as to whether it’s a good use of money from the scientific perspective (I, like others, would argue largely not), there’s also the question of whether it’s a good use of human resources. Having a student or postdoc work on a replication study for years during their training period is not, I think, a good use of their time, and keeps them from the more valuable training experience of actually, you know, doing their own science—let alone robbing them of the thrill of new discovery. Perhaps such studies are best left to industry, which is where I believe they already largely reside.
Saturday, April 8, 2017
The hater’s guide to (experimental) reproducibility
(Thanks to Caroline Bartman and Lauren Beck for discussions.)
Okay, before I start, I just want to emphasize that my lab STRONGLY supports computational reproducibility, and we have released data + code (code all the way from raw data to figures) for all papers primarily from our lab for quite some time now. Just sayin’. We do it because a. we can; b. it enforces a higher standard within the lab; c. on balance, it’s the right thing to do.
All right, that said, I have to say that I find, like many others, the entire conversation about reproducibility right now to be way off the rails, mostly because it’s almost entirely dominated by the statistical point of view. My opinion is that this is totally off base, at least in my particular area of quantitative molecular biology; like I said before, “If you think that github accounts, pre-registered studies and iPython notebooks will magically solve the reproducibility problem, think again.” Yet, it seems that this statistically-dominated perspective is not just a few Twitter people sounding off about Julia and Docker. This "science is falling apart" story has taken hold in the broader media, and the fact that someone like Ioannidis was even being mentioned for director of NIH (!?) shows how deeply and broadly this narrative has taken hold.
Anyway, I won’t rehash all the ways I find this annoying, wrongheaded and in some ways dangerous, I’ll just sum up by saying I’m a hater. But like all haters, deep down, my feelings are fueled by jealousy. :) Jealousy because I actually deeply admire the fact that computational types have spent a lot of time thinking about codifying best practices, and have developed a culture and sense of community standards that embodies those practices. And while I do think that a lot of the moralistic grandstanding from computational folks around these issues is often self-serving, that doesn’t mean that talking about and encouraging computational/statistical reproducibility is a bad thing. Indeed, the fact that statisticians dominate the conversation is not their fault, it’s ours: why is there no experimental equivalent to the (statistical/computational) reproducibility movement?
So first off, the answer is that there is, with lists of validated antibodies and an increased awareness of things like cell line and mycoplasma contamination and so forth. That is all great, but in my experience, these things journals make you check are not typically the reasons for experimental irreproducibility. Fundamentally, these efforts suffer from what I consider a “checklist problem”, which is the idea that reproducibility can be codified into a simple, generic checklist of things. Like, the thought is that if I could just check off all the boxes on mycoplasma and cell identification and animal protocols, then my work would be certified as Reproducible™. This is not to say that we shouldn’t have more checklists (see below), but I just don’t think it’s going to solve the problem.
Okay, so if simplistic checklists aren’t the full solution, then what is? I think the crux of the issue actually comes back to a conversation we had with the venerable Warren Ewens a while back about how to analyze some data we were puzzling over, and he said something to the effect of “There are all these statistical tests we can think about, but it also has to pass the smell test.” This resonated with me, because I realize that that at least some of us experimentalists DO teach reproducibility, but it’s more of an experiential learning to try and impart an intuitive sense of what discrepancies to ignore and which to lose sleep over. In particular in molecular biology, where our tools are imprecise and the systems are (hopelessly?) complex, this intuition is, in my opinion, the single most skill we can teach our trainees.
Okay, before I start, I just want to emphasize that my lab STRONGLY supports computational reproducibility, and we have released data + code (code all the way from raw data to figures) for all papers primarily from our lab for quite some time now. Just sayin’. We do it because a. we can; b. it enforces a higher standard within the lab; c. on balance, it’s the right thing to do.
All right, that said, I have to say that I find, like many others, the entire conversation about reproducibility right now to be way off the rails, mostly because it’s almost entirely dominated by the statistical point of view. My opinion is that this is totally off base, at least in my particular area of quantitative molecular biology; like I said before, “If you think that github accounts, pre-registered studies and iPython notebooks will magically solve the reproducibility problem, think again.” Yet, it seems that this statistically-dominated perspective is not just a few Twitter people sounding off about Julia and Docker. This "science is falling apart" story has taken hold in the broader media, and the fact that someone like Ioannidis was even being mentioned for director of NIH (!?) shows how deeply and broadly this narrative has taken hold.
Anyway, I won’t rehash all the ways I find this annoying, wrongheaded and in some ways dangerous, I’ll just sum up by saying I’m a hater. But like all haters, deep down, my feelings are fueled by jealousy. :) Jealousy because I actually deeply admire the fact that computational types have spent a lot of time thinking about codifying best practices, and have developed a culture and sense of community standards that embodies those practices. And while I do think that a lot of the moralistic grandstanding from computational folks around these issues is often self-serving, that doesn’t mean that talking about and encouraging computational/statistical reproducibility is a bad thing. Indeed, the fact that statisticians dominate the conversation is not their fault, it’s ours: why is there no experimental equivalent to the (statistical/computational) reproducibility movement?
So first off, the answer is that there is, with lists of validated antibodies and an increased awareness of things like cell line and mycoplasma contamination and so forth. That is all great, but in my experience, these things journals make you check are not typically the reasons for experimental irreproducibility. Fundamentally, these efforts suffer from what I consider a “checklist problem”, which is the idea that reproducibility can be codified into a simple, generic checklist of things. Like, the thought is that if I could just check off all the boxes on mycoplasma and cell identification and animal protocols, then my work would be certified as Reproducible™. This is not to say that we shouldn’t have more checklists (see below), but I just don’t think it’s going to solve the problem.
Okay, so if simplistic checklists aren’t the full solution, then what is? I think the crux of the issue actually comes back to a conversation we had with the venerable Warren Ewens a while back about how to analyze some data we were puzzling over, and he said something to the effect of “There are all these statistical tests we can think about, but it also has to pass the smell test.” This resonated with me, because I realize that that at least some of us experimentalists DO teach reproducibility, but it’s more of an experiential learning to try and impart an intuitive sense of what discrepancies to ignore and which to lose sleep over. In particular in molecular biology, where our tools are imprecise and the systems are (hopelessly?) complex, this intuition is, in my opinion, the single most skill we can teach our trainees.
Thing is, some do a much better job of teaching this intuition than others. I think that where we can learn from the computational/statistical reproducibility movement is to try and at least come up with some general principles and guidelines for enhancing the quality of our science, even if they can’t be easily codified. And within a particular lab, I think there are some general good practices, and maybe it’s time to have a more public discussion about them so that we can all learn from each other. So, with all that in mind, here’s our attempt to start a discussion with some ideas for experimental reproducibility, ranging from day-to-day to big picture:
- Keep an online lab notebook that is searchable with links to protocols and is easily shared with other lab members.
- Organize protocols in an online doc that allows for easy sharing and commenting. Avoid protocol "fragmentation"; if a variation comes up, spend the time to build that in as a branch point in the protocol. Otherwise, there will be protocol drift, and others may not know about new improvements.
- Annotate protocols carefully, explaining, where possible, which elements of the protocol are critical and why (and ideally have some documentation). This helps to avoid protocol cruft, where new steps get introduced and reified without reason. Often, leading a new trainee through a protocol is a good time to annotate, since it exposes all the unwritten parts of the protocol. Note: this is also a good way to explore protocol simplification!
- Catalog important lab-generated reagents (probes, plasmids, etc.) with unique identifiers and develop a system for labeling. In the lab, we have a system for labeling and cataloging probes, which helps us figure out post-facto what the difference is between "M20_probe_Cy3" and "M20_probe_Cy3_usethis". What is hard with this is to develop a system for labeling enforcement. Not sure how best to do this. My system is that I won't order any new probes for a person until all their probes are appropriately cataloged.
- Carefully track biologic reagents that are known to suffer from lot variability, including dates, lot numbers, etc. Things like matrigel, antibodies, R-spondin.
- Set up a system for documenting little experiments that establish a little factoid in the lab. Like "Oh, probe length of 30 works best for expansion microscopy based on XYZ…". These can be invaluable down the line, since they're rarely if ever published—and then turn from lab memory into lab lore.
- Journal length limits have led to a culture of very short and non-detailed methods, but there's this thing called the internet that apparently can store and share a lot of information. I think we need to establish a culture of publicly sharing detailed protocols, including annotating all the nuances and so forth. Check out this from Feng Zhang about CRISPR (we also have made an extensive single molecule RNA FISH page here).
- (Lauren) Track experiments in a log, along with all relevant (or even seemingly irrelevant) details. This could be, for instance, a big Google Doc with list of all similar types of experiments, pointing to where the data is kept, and critically, all the little details. These tabulated forms of lab notebooks can really help identify patterns in those little details, but also serve to show other members of the lab what details matter and that they should be attentive to.
- Along those lines, record all your failures, along with the type of failure. We've definitely had times when we could have saved a lot of time in the lab if we had kept track of that. SHARE FAILURES with others in the lab, especially the PI.
- (Caroline) Establish an objective baseline for an experiment working, and stick to it. Sort of like pre-registering your experiment, in a way. If you take data, what will allow you to say that it worked or didn't work. If it didn't work, is there a rationalization? If so, discuss with someone, including the PI, to make sure you aren't deluding yourself and just ignoring data you don't like. There are often good reasons to drop bits of data, and sometimes we make mistakes in our judgement calls, but at least get a second opinion.
- Develop lab-specific checklists. Every lab has it's own set of things it cares about and that people should check, like microscope light intensity or probe HPLC trace or whatever. Usually these are taught and learned through experience, but that strikes me as less efficient than it could be.
- Replicates: What constitutes a biological replicate? Is it the same batch of cells grown in two wells? Is it two separate passages of the same cell line? If so, separated by how much time? Or do you want to start each one fresh from a frozen vial? Whatever your system, it's important to come up with some ground rules for what replicates means, and then stick to it. I feel like one aspect of replication is that you don't want the conditions to be necessarily exactly the same, so a little variability is good. After all, that's what separates a biological replicate (which is really about capturing systematic but unknown variability) from a technical replicate (which is statistically variability).
- Have someone else take a look at your data without leading them too much with your hypothesis. Do they follow the same logic to reach the same conclusion? Many times, people fall so in love with their crazy hypothesis that they fail to see the simpler (and far more plausible) boring explanation instead. (Former postdoc Gautham Nair was so good at finding the simple boring explanation that we called it the "Gautham transform" in the lab!)
- Critically examine parts that don't fit in the story. No story is perfect, especially in molecular biology, which has a serious "everything affects everything" problem. Often times there is no explanation, and there's nothing you can really do about it. Okay, but resist the urge to sweep it under the rug. Sometimes there's new science in there!
- Finally, there is no substitute for just thinking long and hard about your work with a critical mindset. Everything else is just, like I said, a checklist, nothing more, nothing less.
Anyway, some thoughts, and I'm guessing most people already do a lot of this, implicitly or explicitly. We'd love to hear the probably huge list of other ideas people out there have for improving the quality/reproducibility of their science. Point is, let's have a public discussion so that everyone can participate!
Saturday, June 11, 2016
Some thoughts on lab communication
I recently came across this nice post about tough love in science:
https://ambikamath.wordpress.com/2016/05/16/on-tough-love-in-science/and this passage at the start really stuck out:
My very first task in the lab as an undergrad was to pull layers of fungus off dozens of cups of tomato juice. My second task was PCR, at which I initially excelled. Cock-sure after a week of smaller samples, I remember confidently attempting an 80-reaction PCR, with no positive control. Every single reaction failed…
I vividly recall a flash of disappointment across the face of one of my PIs, probably mourning all that wasted Taq. That combination—“this happens to all of us, but it really would be best if it didn’t happen again”—was exactly what I needed to keep going and to be more careful.
Now, communication is easy when it's all like "Hey, I've got this awesome idea, what do you think?" "Oh yeah, that's the best idea ever!" "Boo-yah!" [secret handshake followed by football head-butt]. What I love about this quote is how it perfectly highlights how good communication can inspire and reassure, even in a tough situation—and how bad communication can lead to humiliation and disengagement.
I'm sure there are lots of theories and data out there about communication (or not :)), but when it comes down to putting things into practice, I've found that having simple rules or principles is often a lot easier to follow and to quantify. One that has been particularly effective for me is to avoid "you" language, which is the ultimate simple rule: just avoid saying "you"! Now that I've been following that rule for some time and thinking about why it's so effective at improving communication, I think there's a relatively simple principle beneath it that is helpful as well: if you're saying something for someone else's benefit, then good. If you're saying something for your own benefit, then bad. Do more of the former, less of the latter.
How does this work out in practice? Let's take the example from the quote above. As a (disappointed) human being, your instinct is going to be to think "Oh man, how could you have done that!?" A simple application of no-you-language will help you avoid saying this obviously bad thing. But there are counterproductive no-you-language ways to respond as well: "Well, that was disappointing!" "That was a big waste" "I would really double check things before doing that again". Perhaps the first two of these are straightforwardly incorrect, but I think the last one is counterproductive as well. Let's dissect the real reasons you would say "I would really double check before doing that again". Now, of course the trainee is going to be feeling pretty awful—people generally know when they've screwed up, especially if they screwed up bad. Anyone with a brain knows that if you screw up big, you should probably double check and be more careful. So what's the real reasoning behind telling someone to double check? It's basically to say "I noticed you screwed up and you should be more careful." Ah, the hidden you language revealed! What this sentence is really about is giving yourself the opportunity to vent your frustration with the situation.
So what to say? I think the answer is to take a step back, think about the science and the person, and come up with something that is beneficial to the trainee. If they're new, maybe "Running a positive control every time is really a good idea." (unless they already realized that mistake). Or "Whenever I scale up the reaction, I always check…" These bits of advice often work well when coupled with a personal story, like "I remember when I screwed up one of these big ones early on, and what I found helped me was…". I will sometimes use another mythic figure from the lab's recent past, since I'm old enough now that personal lab stories sound a little too "crazy old grandpa" to be very effective…
It is also possible that there is nothing to learn from this mistake and that it was just, well, a mistake. In which case, there is nothing you can say that is for anyone's benefit other than yourself, and in those situations, it really is just better to say nothing. This can take a lot of discipline, because it's hard not to express those sorts of feelings right when they're hitting you the hardest. But it's worth it. If it's a repeated issue that's really affecting things, there are two options: 1. address it later during a performance review, or 2. don't. Often, with those sorts of issues, there's honestly not much difference in outcome between these options, so maybe it's just better to go with 2.
Another common category of negative communication are all the sundry versions of "I told you so". This is obviously something you say for your own benefit rather than the other person, and indeed it is so clearly accusatory that most folks know not to say this specific phrase. But I think this is just one of a class of what I call "scorekeeping" statements, which are ones that serve only to remind people of who was right or wrong. Like "But I thought we agreed to…" or "Last time I was supposed to…" They're very tempting, because as scientists we are in the business of telling each other that we're right and wrong, but when you're working with someone in the lab, scoring these types of points is corrosive in the long term. Just remember that the next time your PI asks you to change the figure back the other way around for the 4th time… :)
Along those lines, I think it's really important for trainees (not just PIs) to think about how to improve their communication skills as well. One thing I hear often is "Before I was a PI, I got all this training in science, and now I'm suddenly supposed to do all this stuff I wasn't trained for, like managing people". I actually disagree with this. To me, the concept of "managing people" is sort of a misnomer, because in the ideal case, you're not really "managing" anyone at all, but rather working with them as equals. That implies an equal stake in and commitment to productive communications on both ends, which also means that there are opportunities to learn and improve for all parties. I urge trainees to take advantage of those opportunities. Few of us are born with perfect interpersonal skills, especially in work situations, and extra especially in science, where things change and go wrong all the time, practically begging people to assign blame to each other. It's a lot of work, but a little practice and discipline in this area can go a long way.
I'm sure there are lots of theories and data out there about communication (or not :)), but when it comes down to putting things into practice, I've found that having simple rules or principles is often a lot easier to follow and to quantify. One that has been particularly effective for me is to avoid "you" language, which is the ultimate simple rule: just avoid saying "you"! Now that I've been following that rule for some time and thinking about why it's so effective at improving communication, I think there's a relatively simple principle beneath it that is helpful as well: if you're saying something for someone else's benefit, then good. If you're saying something for your own benefit, then bad. Do more of the former, less of the latter.
How does this work out in practice? Let's take the example from the quote above. As a (disappointed) human being, your instinct is going to be to think "Oh man, how could you have done that!?" A simple application of no-you-language will help you avoid saying this obviously bad thing. But there are counterproductive no-you-language ways to respond as well: "Well, that was disappointing!" "That was a big waste" "I would really double check things before doing that again". Perhaps the first two of these are straightforwardly incorrect, but I think the last one is counterproductive as well. Let's dissect the real reasons you would say "I would really double check before doing that again". Now, of course the trainee is going to be feeling pretty awful—people generally know when they've screwed up, especially if they screwed up bad. Anyone with a brain knows that if you screw up big, you should probably double check and be more careful. So what's the real reasoning behind telling someone to double check? It's basically to say "I noticed you screwed up and you should be more careful." Ah, the hidden you language revealed! What this sentence is really about is giving yourself the opportunity to vent your frustration with the situation.
So what to say? I think the answer is to take a step back, think about the science and the person, and come up with something that is beneficial to the trainee. If they're new, maybe "Running a positive control every time is really a good idea." (unless they already realized that mistake). Or "Whenever I scale up the reaction, I always check…" These bits of advice often work well when coupled with a personal story, like "I remember when I screwed up one of these big ones early on, and what I found helped me was…". I will sometimes use another mythic figure from the lab's recent past, since I'm old enough now that personal lab stories sound a little too "crazy old grandpa" to be very effective…
It is also possible that there is nothing to learn from this mistake and that it was just, well, a mistake. In which case, there is nothing you can say that is for anyone's benefit other than yourself, and in those situations, it really is just better to say nothing. This can take a lot of discipline, because it's hard not to express those sorts of feelings right when they're hitting you the hardest. But it's worth it. If it's a repeated issue that's really affecting things, there are two options: 1. address it later during a performance review, or 2. don't. Often, with those sorts of issues, there's honestly not much difference in outcome between these options, so maybe it's just better to go with 2.
Another common category of negative communication are all the sundry versions of "I told you so". This is obviously something you say for your own benefit rather than the other person, and indeed it is so clearly accusatory that most folks know not to say this specific phrase. But I think this is just one of a class of what I call "scorekeeping" statements, which are ones that serve only to remind people of who was right or wrong. Like "But I thought we agreed to…" or "Last time I was supposed to…" They're very tempting, because as scientists we are in the business of telling each other that we're right and wrong, but when you're working with someone in the lab, scoring these types of points is corrosive in the long term. Just remember that the next time your PI asks you to change the figure back the other way around for the 4th time… :)
Along those lines, I think it's really important for trainees (not just PIs) to think about how to improve their communication skills as well. One thing I hear often is "Before I was a PI, I got all this training in science, and now I'm suddenly supposed to do all this stuff I wasn't trained for, like managing people". I actually disagree with this. To me, the concept of "managing people" is sort of a misnomer, because in the ideal case, you're not really "managing" anyone at all, but rather working with them as equals. That implies an equal stake in and commitment to productive communications on both ends, which also means that there are opportunities to learn and improve for all parties. I urge trainees to take advantage of those opportunities. Few of us are born with perfect interpersonal skills, especially in work situations, and extra especially in science, where things change and go wrong all the time, practically begging people to assign blame to each other. It's a lot of work, but a little practice and discipline in this area can go a long way.
Thursday, March 3, 2016
From over-reproducibility to a reproducibility wish-list
Well, it’s clear that that last blog post on over-reproducibility touched a bit of a nerve. ;)
Anyway, lot of the feedback was rather predictable and not particularly convincing, but I was pointed to this discussion on the software carpentry website, which was actually really nice:
On 2016-03-02 1:51 PM, Steven Haddock wrote:
> It is interesting how this has morphed into a discussion of ways to convince / teach git to skeptics, but I must say I agreed with a lot of the points in the RajLab post.
>
> Taking a realistic and practical approach to use of computing tools is not something that needs to be shot down (people sound sensitive!). Even if you can’t type `make paper` to recapitulate your work, you can still be doing good science…
>
+1 (at least) to both points. What I've learned from this is that many scientists still see cliffs where they want on-ramps; better docs and lessons will help, but we really (really) to put more effort into usability and interoperability. (Diff and merge for spreadsheets!)
So let me turn this around and ask Arjun: what would it take to convince you that it *was* worth using version control and makefiles and the like to manage your work? What would you, as a scientist, accept as compelling?
Thanks,
Greg
--
Dr Greg Wilson
Director of Instructor Training
Software Carpentry Foundation
First off, thanks to Greg for asking! I really appreciate the active attempt to engage.
Secondly, let me just say that as to the question of what it would take for us to use version control, the answer is nothing at all, because we already use it! More specifically, we use it in places where we think it’s most appropriate and efficient.
I think it may be helpful for me to explain what we do in the lab and how we got here. Our lab works primarily on single cell biology, and our methods are primarily single molecule/single cell imaging techniques and, more recently, various sequencing techniques (mostly RNA-seq, some ATAC-seq, some single cell RNA-seq). My lab has people with pretty extensive coding experience and people with essentially no coding experience, and many in between (I see it as part of my educational mission to try and get everyone to get better at coding during their time in the lab). My PhD is in applied math with a side of molecular biology, during which time we developed a lot of the single RNA molecule techniques that we are still using today. During my PhD, I was doing the computational parts of my science in an only vaguely reproducible way, and that scared me. Like “Hmm, that data point looks funny, where did that come from?”. Thus, in my postdoc, I started developing a little MATLAB "package" for documenting and performing image analysis. I think this is where our first efforts in computational reproducibility began.
When I started in the lab in 2010, my (totally awesome) first student Marshall and I took the opportunity to refactor our image analysis code, and we decided to adopt version control for these general image processing tools. After a bit of discussion, we settled on Mercurial and bitbucket.org because it was supposed to be easier to use than git. This has served us fairly well. Then, my brilliant former postdoc Gautham got way into software engineering and completely refactored our entire image processing pipeline, which is basically what we are using today, and is the version that we point others to use here. Since then, various people have contributed modules and so forth. For this sort of work, version control is absolutely essential: we have a team of people contributing to a large, complex codebase that is used by many people in the lab. No brainer.
In our work, we use these image processing tools to take raw data and turn it into numbers that we then use to hopefully do some science. This involves the use of various analysis scripts that will take this data, perform whatever statistical analysis and so forth on it, and then turn that into a graphical element. Typically, this is done by one, more often two, people in the lab, typically working closely together.
On 2016-03-02 1:51 PM, Steven Haddock wrote:
> It is interesting how this has morphed into a discussion of ways to convince / teach git to skeptics, but I must say I agreed with a lot of the points in the RajLab post.
>
> Taking a realistic and practical approach to use of computing tools is not something that needs to be shot down (people sound sensitive!). Even if you can’t type `make paper` to recapitulate your work, you can still be doing good science…
>
+1 (at least) to both points. What I've learned from this is that many scientists still see cliffs where they want on-ramps; better docs and lessons will help, but we really (really) to put more effort into usability and interoperability. (Diff and merge for spreadsheets!)
So let me turn this around and ask Arjun: what would it take to convince you that it *was* worth using version control and makefiles and the like to manage your work? What would you, as a scientist, accept as compelling?
Thanks,
Greg
--
Dr Greg Wilson
Director of Instructor Training
Software Carpentry Foundation
First off, thanks to Greg for asking! I really appreciate the active attempt to engage.
Secondly, let me just say that as to the question of what it would take for us to use version control, the answer is nothing at all, because we already use it! More specifically, we use it in places where we think it’s most appropriate and efficient.
I think it may be helpful for me to explain what we do in the lab and how we got here. Our lab works primarily on single cell biology, and our methods are primarily single molecule/single cell imaging techniques and, more recently, various sequencing techniques (mostly RNA-seq, some ATAC-seq, some single cell RNA-seq). My lab has people with pretty extensive coding experience and people with essentially no coding experience, and many in between (I see it as part of my educational mission to try and get everyone to get better at coding during their time in the lab). My PhD is in applied math with a side of molecular biology, during which time we developed a lot of the single RNA molecule techniques that we are still using today. During my PhD, I was doing the computational parts of my science in an only vaguely reproducible way, and that scared me. Like “Hmm, that data point looks funny, where did that come from?”. Thus, in my postdoc, I started developing a little MATLAB "package" for documenting and performing image analysis. I think this is where our first efforts in computational reproducibility began.
When I started in the lab in 2010, my (totally awesome) first student Marshall and I took the opportunity to refactor our image analysis code, and we decided to adopt version control for these general image processing tools. After a bit of discussion, we settled on Mercurial and bitbucket.org because it was supposed to be easier to use than git. This has served us fairly well. Then, my brilliant former postdoc Gautham got way into software engineering and completely refactored our entire image processing pipeline, which is basically what we are using today, and is the version that we point others to use here. Since then, various people have contributed modules and so forth. For this sort of work, version control is absolutely essential: we have a team of people contributing to a large, complex codebase that is used by many people in the lab. No brainer.
In our work, we use these image processing tools to take raw data and turn it into numbers that we then use to hopefully do some science. This involves the use of various analysis scripts that will take this data, perform whatever statistical analysis and so forth on it, and then turn that into a graphical element. Typically, this is done by one, more often two, people in the lab, typically working closely together.
Right around the time Gautham left the lab, we had several discussions about software best practices in the lab. Gautham argued that every project should have a repository for these analysis scripts. He also argued that the commit history could serve as a computational lab notebook. At the time, I thought the idea of a repo for every project was a good one, and I cajoled people in the lab into doing it. I pretty quickly pushed back on the version-control-as-computational-lab-notebook claim, and I still feel that pretty strongly. I think it’s interesting to think about why. Version control is a tool that allows you to keep track of changes to code. It is not something that will naturally document what that code does. My feeling is that version control is in some ways a victim of its own success: it is such a useful tool for managing code that it is now widely used and promoted, and as a side-effect it is now being used for a lot of thing for which it is not quite the right tool for the job, a point I’ll come back to.
Fast forward a little bit. Using version control in the repo-for-every-project model was just not working for most people in the lab. To give a sense of what we’re doing, in most projects, there’s a range of analyses, sometimes just making a simple box-plot or bar graph, sometimes long-ish scripts that take, say, RNA counts per cell and fit to a model of RNA production, extracting model parameters with error bounds. Sometimes it might be something still more complicated. The issue with version control in this scenario is all the headache. Some remote heads would get forked. Somehow things weren't syncing right. Some other weird issue would come up. Plus, frankly all the commit/push/pull/update was causing some headaches, especially if someone forgot to push. One student in the lab and I were just working on a large project together, and after bumping into these issues over and over, she just said “screw it, can we just use Dropbox?” I was actually reluctant at first, but then I thought about it a bit more. What were we really losing? As I mention in the blog post, our goal is a reproducible analysis. For this, versioning is at best a means towards this goal, and in practice for us, a relatively tangential means. Yes, you can go back and use earlier versions. Who cares? The number of times we’ve had to do that in this context is basically zero. One case people have mentioned as a potential benefit for version control is performing alternative, exploratory analyses on a particular dataset, the idea being you can roll back and compare results. I would argue that version control is not the best way to perform or document this. Let’s set I have a script for “myCoolAnalysis”. What we do in lab is make “myAlternativeAnalysis” in which we code our new analysis. Now I can easily compare. Importantly, we have both versions around. The idea of keeping the alternative version in version control is I think a bad one: it’s not discoverable except by searching the commit log. Let’s say that you wanted to go back to that analysis in the future. How would I find it? I think it makes much more sense to have it present in the current version of the code than to dig through the commit history. One could argue that you could fork the repo, but then changes to other, unrelated parts of the repo would be hard to deal with. Overall, version control is just not the right tool for this, in my opinion.
Another, somewhat related point that people have raised is looking back to see why some particular output changed. Here, we’re basically talking about bugs/flawed analyses. There is some merit to this, and so I acknowledge there is a tradeoff, and that once you get to a certain scale, version control is very helpful. However, I think that for scientific programming at the scale I’m talking about, it’s usually fairly clear what caused something to change, and I’m less concerned about why something changed and much more worried about whether we’re actually getting the right answer, which is always a question about the code as it stands. For us, the vast majority of the time, we are moving forward. I think the emphasis here would be better on teaching people about how to test their code (which is a scientific problem more than a programming problem) than version control.
Which leads me to really answering the question: what would I love to have in the lab? On a very practical level, look, version control is still just too hard and annoying to use for a lot of people and injects a lot of friction into the process. I have some very smart people in my lab, and we all have struggled from time to time. I’m sure we can figure it out, but honestly, I see little impetus to do so for the use cases outlined above, and yes, our work is 100% reproducible without it. Moving (back) to Dropbox has been a net productivity win, allowing us to work quickly and efficiently together. Also, the hassle free nature of it was a real relief. On our latest project, while using version control, we were always asking “oh, did you push that?”, “hmm, what happened?”, “oh, I forgot to update”. (And yes, we know about and sometimes use SourceTree.) These little hassles all add up to a real cognitive burden, and I’m sorry, but it's just a plain fact that Dropbox is less work. Now it’s just “Oh, I updated those graphs”, “Looks great, nice!”. Anyway, what I would love is Dropbox with a little bit more version tracking. And Dropbox does have some rudimentary versioning, basically a way to recover from an "oh *#*$" moment–the thing I miss most is probably a quick diff. Until this magical system emerges, though, on balance, it is currently just more efficient for us not to use version control for this type of computational work. I posit that the majority of people who could benefit from some minimal computational reproducibility practices fall into this category as well.
Testing: I think getting people in the habit of testing would be a huge move in the right direction. And I think this means scientific code testing, not just “program doesn’t crash” testing. When I teach my class on molecular systems biology, one of my secret goals is to teach students a little bit about scientific programming. For those who have some programming experience, they often fall into the trap of thinking “well, the program ran, so it must have worked”, which is often fine for, say, a website or something, but it’s usually just the beginning of the story for scientific programming and simulations. Did you look for the order of convergence (or convergence at all)? Did you look for whether you’re getting the predicted distribution in a well-known degenerate case? Most people don’t think about programming that way. Note that none of this has anything to do with version control per se.
On a bigger level, I think the big unmet need is that of a nice way to document an analysis as it currently stands. Gautham and I had a lot of discussions about this when he was in lab. What would such documentation do? Ideally, it would document the analysis in a searchable and discoverable way. This was something Gautham and I discussed at length and didn’t get around to implementing. Here’s one idea we were tossing around. Let’s say that you kept your work in a directory tree structure, with analyses organized by subfolder. Like, could keep that analysis of H3K4me3 in “histoneModificationComparisons/H3K4me3/”, then H3K27me3 in “histoneModificationComparisons/H3K27me3/”. In each directory, you have the scripts associated with a particular analysis, and then running those scripts produces an output graph. That output graph could either be stored in the same folder or in a separate “graphs” subfolder. Now, the scripts and the graphs would have metadata (not sure what this would look like in practice), so you could have a script go through and quickly generate a table of contents with links to all these graphs for easy display and search. Perhaps this is similar to those IPython notebooks or whatever. Anyway, the main features is that this would make all those analyses (including older ones that don't make it in the paper) discoverable (via tagging/table of contents) and searchable (search:“H3K27”). For me, this would be a really helpful way to document an analysis, and would be relatively lightweight and would fit into our current workflow. Which reminds me: we should do this.
I also think that a lot of this discussion is really sort of veering around the simple task of keeping a computational lab notebook. This is basically a narrative about what you tried, what worked, what didn’t work, and how you did it, why you did it, and what you learned. I believe there have been a lot of computational lab notebook attempts out there, from essentially keyloggers on up, and I don’t know of any that have really taken off. I think the main thing that needs to change there is simply the culture. Version control is not a notebook, keylogging is not a notebook, the only thing that is a notebook is you actually spending the time to write down what you did, carefully and clearly–just like in the lab. When I have cajoled people in the lab into doing this, the resulting documents have been highly useful to others as how-to guides and as references. There have been depressingly few such documents, though.
Also, seriously, let's not encourage people to use version control for maintaining their papers. This is just about the worst way to sell version control. Unless you're doing some heavy math with LaTeX or working with a very large document, Google Docs or some equivalent is the clear choice every time, and it will be impossible to convince me otherwise. Version control is a tool for maintaining code. It was never meant for managing a paper. Much better tools exist. For instance, Google Docs excels at easy sharing, collaboration, simultaneous editing, commenting and reply-to-commenting. Sure, one can approximate these using text-based systems and version control. The question is why anyone would like to do that. Not everything you do on a computer maps naturally to version control.
Fast forward a little bit. Using version control in the repo-for-every-project model was just not working for most people in the lab. To give a sense of what we’re doing, in most projects, there’s a range of analyses, sometimes just making a simple box-plot or bar graph, sometimes long-ish scripts that take, say, RNA counts per cell and fit to a model of RNA production, extracting model parameters with error bounds. Sometimes it might be something still more complicated. The issue with version control in this scenario is all the headache. Some remote heads would get forked. Somehow things weren't syncing right. Some other weird issue would come up. Plus, frankly all the commit/push/pull/update was causing some headaches, especially if someone forgot to push. One student in the lab and I were just working on a large project together, and after bumping into these issues over and over, she just said “screw it, can we just use Dropbox?” I was actually reluctant at first, but then I thought about it a bit more. What were we really losing? As I mention in the blog post, our goal is a reproducible analysis. For this, versioning is at best a means towards this goal, and in practice for us, a relatively tangential means. Yes, you can go back and use earlier versions. Who cares? The number of times we’ve had to do that in this context is basically zero. One case people have mentioned as a potential benefit for version control is performing alternative, exploratory analyses on a particular dataset, the idea being you can roll back and compare results. I would argue that version control is not the best way to perform or document this. Let’s set I have a script for “myCoolAnalysis”. What we do in lab is make “myAlternativeAnalysis” in which we code our new analysis. Now I can easily compare. Importantly, we have both versions around. The idea of keeping the alternative version in version control is I think a bad one: it’s not discoverable except by searching the commit log. Let’s say that you wanted to go back to that analysis in the future. How would I find it? I think it makes much more sense to have it present in the current version of the code than to dig through the commit history. One could argue that you could fork the repo, but then changes to other, unrelated parts of the repo would be hard to deal with. Overall, version control is just not the right tool for this, in my opinion.
Another, somewhat related point that people have raised is looking back to see why some particular output changed. Here, we’re basically talking about bugs/flawed analyses. There is some merit to this, and so I acknowledge there is a tradeoff, and that once you get to a certain scale, version control is very helpful. However, I think that for scientific programming at the scale I’m talking about, it’s usually fairly clear what caused something to change, and I’m less concerned about why something changed and much more worried about whether we’re actually getting the right answer, which is always a question about the code as it stands. For us, the vast majority of the time, we are moving forward. I think the emphasis here would be better on teaching people about how to test their code (which is a scientific problem more than a programming problem) than version control.
Which leads me to really answering the question: what would I love to have in the lab? On a very practical level, look, version control is still just too hard and annoying to use for a lot of people and injects a lot of friction into the process. I have some very smart people in my lab, and we all have struggled from time to time. I’m sure we can figure it out, but honestly, I see little impetus to do so for the use cases outlined above, and yes, our work is 100% reproducible without it. Moving (back) to Dropbox has been a net productivity win, allowing us to work quickly and efficiently together. Also, the hassle free nature of it was a real relief. On our latest project, while using version control, we were always asking “oh, did you push that?”, “hmm, what happened?”, “oh, I forgot to update”. (And yes, we know about and sometimes use SourceTree.) These little hassles all add up to a real cognitive burden, and I’m sorry, but it's just a plain fact that Dropbox is less work. Now it’s just “Oh, I updated those graphs”, “Looks great, nice!”. Anyway, what I would love is Dropbox with a little bit more version tracking. And Dropbox does have some rudimentary versioning, basically a way to recover from an "oh *#*$" moment–the thing I miss most is probably a quick diff. Until this magical system emerges, though, on balance, it is currently just more efficient for us not to use version control for this type of computational work. I posit that the majority of people who could benefit from some minimal computational reproducibility practices fall into this category as well.
Testing: I think getting people in the habit of testing would be a huge move in the right direction. And I think this means scientific code testing, not just “program doesn’t crash” testing. When I teach my class on molecular systems biology, one of my secret goals is to teach students a little bit about scientific programming. For those who have some programming experience, they often fall into the trap of thinking “well, the program ran, so it must have worked”, which is often fine for, say, a website or something, but it’s usually just the beginning of the story for scientific programming and simulations. Did you look for the order of convergence (or convergence at all)? Did you look for whether you’re getting the predicted distribution in a well-known degenerate case? Most people don’t think about programming that way. Note that none of this has anything to do with version control per se.
On a bigger level, I think the big unmet need is that of a nice way to document an analysis as it currently stands. Gautham and I had a lot of discussions about this when he was in lab. What would such documentation do? Ideally, it would document the analysis in a searchable and discoverable way. This was something Gautham and I discussed at length and didn’t get around to implementing. Here’s one idea we were tossing around. Let’s say that you kept your work in a directory tree structure, with analyses organized by subfolder. Like, could keep that analysis of H3K4me3 in “histoneModificationComparisons/H3K4me3/”, then H3K27me3 in “histoneModificationComparisons/H3K27me3/”. In each directory, you have the scripts associated with a particular analysis, and then running those scripts produces an output graph. That output graph could either be stored in the same folder or in a separate “graphs” subfolder. Now, the scripts and the graphs would have metadata (not sure what this would look like in practice), so you could have a script go through and quickly generate a table of contents with links to all these graphs for easy display and search. Perhaps this is similar to those IPython notebooks or whatever. Anyway, the main features is that this would make all those analyses (including older ones that don't make it in the paper) discoverable (via tagging/table of contents) and searchable (search:“H3K27”). For me, this would be a really helpful way to document an analysis, and would be relatively lightweight and would fit into our current workflow. Which reminds me: we should do this.
I also think that a lot of this discussion is really sort of veering around the simple task of keeping a computational lab notebook. This is basically a narrative about what you tried, what worked, what didn’t work, and how you did it, why you did it, and what you learned. I believe there have been a lot of computational lab notebook attempts out there, from essentially keyloggers on up, and I don’t know of any that have really taken off. I think the main thing that needs to change there is simply the culture. Version control is not a notebook, keylogging is not a notebook, the only thing that is a notebook is you actually spending the time to write down what you did, carefully and clearly–just like in the lab. When I have cajoled people in the lab into doing this, the resulting documents have been highly useful to others as how-to guides and as references. There have been depressingly few such documents, though.
Also, seriously, let's not encourage people to use version control for maintaining their papers. This is just about the worst way to sell version control. Unless you're doing some heavy math with LaTeX or working with a very large document, Google Docs or some equivalent is the clear choice every time, and it will be impossible to convince me otherwise. Version control is a tool for maintaining code. It was never meant for managing a paper. Much better tools exist. For instance, Google Docs excels at easy sharing, collaboration, simultaneous editing, commenting and reply-to-commenting. Sure, one can approximate these using text-based systems and version control. The question is why anyone would like to do that. Not everything you do on a computer maps naturally to version control.
Anyway, that ended up being a pretty long response to what was a fairly short question, but I also just want to reiterate that I find it reassuring that people like Greg are willing to listen to these ramblings and hopefully find something positive from it. My lab is really committed to reproducible computational analyses, and I think I speak for many when I describe the challenges we and others face in making it happen. Hopefully this can stimulate some new discussion and ideas!
Sunday, February 28, 2016
From reproducibility to over-reproducibility
[See also follow up post.]
It's no secret that biomedical research is requiring more and more computational analyses these days, and with that has come some welcome discussion of how to make those analyses reproducible. On some level, I guess it's a no-brainer: if it's not reproducible, it's not science, right? And on a practical level, I think there are a lot of good things about making your analysis reproducible, including the following (vaguely ranked starting with what I consider most important):
My worry, however, is that the strategies for reproducibility that computational types are often promoting are off-target and not necessarily adapted for the needs and skills of the people they are trying to reach. There is a certain strain of hyper-reproducible zealotry that I think is discouraging others to adopt some basic practices that could greatly benefit their research, and at the same time is limiting the productivity of even its own practitioners. You know what I'm talking about: it's the idea of turning your entire paper into a program, so you just type "make paper" and out pops the fully formed and formatted manuscript. Fine in the abstract, but in a line of work (like many others) in which time is our most precious commodity, these compulsions represent a complete failure to correctly measure opportunity costs. In other words, instead of hard coding the adjustment of the figure spacing of your LaTeX preprint, spend that time writing another paper. I think it’s really important to remember that our job is science, not programming, and if we focus too heavily on the procedural aspects of making everything reproducible and fully documented, we risk turning off those who are less comfortable with programming from the very real benefits of making their analysis reproducible.
Here are the two biggest culprits in my view: version control and figure scripting.
Let's start with version control. I think we can all agree that the most important part of making a scientific analysis reproducible is to make sure the analysis is in a script and not just typed or clicked into a program somewhere, only for those commands to vanish into faded memory. A good, reproducible analysis script should start with raw data, go through all the computational manipulations required, and leave you with a number or graphical element that ends up in your paper somewhere. This makes the analysis reproducible, because someone else can now just run the code and see how your raw data turned into that p-value in subpanel Figure 4G. And remember, that someone else is most likely your future self :).
Okay, so we hopefully all agree on the need for scripts. Then, however, almost every discussion about computational reproducibility begins with a directive to adopt git or some other version control system, as though it’s the obvious next step. Hmm. I’m just going to come right out and say that for the majority of computational projects (at least in our lab), version control is a waste of time. Why? Well, what is the goal of making a reproducible analysis? I believe the goal is to have a documented set of scripts that take raw data and reliably turn it into a bit of knowledge of some kind. The goal of version control is to manage code, in particular emphasizing “reversibility, concurrency, and annotation [of changes to code]”. While one can imagine some overlap between these goals, I don’t necessarily see a natural connection between them. To make that more concrete, let’s try to answer the question that I’ve been asking (and been asked), which is “Why not just use Dropbox?”. After all, Dropbox will keep all your code and data around (including older versions), shared between people seamlessly, and probably will only go down if WWIII breaks out. And it's easy to use. Here are a few potential arguments I can imagine people might make in favor of version control:
Which brings us then to point 2, about tracking code changes. In thinking about this, I think it’s useful to separate out code that is for general purpose tools in the lab and code that is specific for a particular project. For code for general purpose tools that multiple team members are contributing to, version control makes a lot of sense–that’s what it was really designed for, after all. It’s very helpful to see older versions of the codebase, see the exact changes that other members of the team have made, and so forth.
These rationales don’t really apply, though, to code that people will write for analyzing data for a particular project. In our lab, and I suspect most others, this code is typically written by one or two people, and if two, they’re typically working in very close contact. Moreover, the end goal is not to have a record of a shifting codebase, but rather to have a single, finalized set of analysis scripts that will reproduce the figures and numbers in the paper. For this reason, the ability to roll back to previous versions of the code and annotate changes is of little utility in practice. I asked around lab, and I think there was maybe one time when we rolled back code. Otherwise, basically, for most analyses for papers, we just move forward and don’t worry about it. I suppose there is theoretically the possibility that some old analysis could prove useful that you could recover through version control, but honestly, most of the time, that ends up in a separate folder anyway. (One might say that’s not clean, but I think that it’s actually just fine. If an analysis is different in kind, then replacing it via version control doesn’t really make sense–it’s not a replacement of previous code per se.)
Of course, one could say, well, even if version control isn’t strictly necessary for reproducible analyses, what does it hurt? In my opinion, the big negative is the amount of friction version control injects into virtually every aspect of the analysis process. This is the price you pay for versioning and annotation, and I think there’s no way to get around that. With Dropbox, I just stick a file in and it shows up everywhere, up to date, magically. No muss, no fuss. If you use version control, it’s constant committing, pushing, pulling, updating, and adding notes. Moreover, if you’re like me, you will screw up at some point, leading to some problem, potentially catastrophic, that you will spend hours trying to figure out. I’m clearly not alone:
 “Abort: remote heads forked” anyone? :) At that point, we all just call over the one person in lab who knows how to deal with all this crap and hope for the best. And look, I’m relatively computer savvy, so I can only imagine how intimidating all this is for people who are less computer savvy. The bottom line is that version control is cumbersome, arcane and time-consuming, and most importantly, doesn’t actually contribute much to a reproducible computational analysis. If the point is to encourage people who are relatively new to computation to make scripts and organize their computational results, I think directing them adopt version control is a very bad idea. Indeed, for a while I was making everyone in our lab use version control for their projects, and overall, it has been a net negative in terms of time. We switched to Dropbox for a few recent projects and life is MUCH better–and just as reproducible.
“Abort: remote heads forked” anyone? :) At that point, we all just call over the one person in lab who knows how to deal with all this crap and hope for the best. And look, I’m relatively computer savvy, so I can only imagine how intimidating all this is for people who are less computer savvy. The bottom line is that version control is cumbersome, arcane and time-consuming, and most importantly, doesn’t actually contribute much to a reproducible computational analysis. If the point is to encourage people who are relatively new to computation to make scripts and organize their computational results, I think directing them adopt version control is a very bad idea. Indeed, for a while I was making everyone in our lab use version control for their projects, and overall, it has been a net negative in terms of time. We switched to Dropbox for a few recent projects and life is MUCH better–and just as reproducible.
Oh, and I think there are some people who use version control for the text of their papers (almost certainly a proper subset of those who are for some reason writing their papers in Markdown or LaTeX). Unless your paper has a lot of math in it, I have no idea why anyone would subject themselves to this form of torture. Let me be the one to tell you that you are no less smart or tough if you use Google Docs. In fact, some might say you’re more smart, because you don’t let command-line ethos/ideology get in the way of actually getting things done… :)
Which brings me to the example of figure scripting. Figure scripting is the process of making a figure completely from a script. Such a script will make all the subpanels, adjust all the font sizes, deal with all the colors, and so forth. In an ideal world with infinite time, this would be great–who wouldn't want to make all their figures magically appear by typing make figures? In practice, there are definitely some diminishing returns, and it's up to you where the line is between making it reproducible and getting it done. For me, the hard line is that all graphical elements representing data values should be coded. Like, if I make a scatterplot, then the locations of the points relatively to axes should be hard coded. Beyond that, Illustrator time! Illustrator will let you set the font size, the line weighting, marker color, and virtually every other thing you can think of simply and relatively intuitively, with immediate feedback. If you can set your font sizes and so forth programmatically, more power to you. But it's worth keeping in mind that the time you spend programming these things is time you could be spending on something else. This time can be substantial: check out this lengthy bit of code written to avoid a trip to Illustrator. Also, as the complexity of what you're trying to do gets greater, the fewer packages there are to help you make your figure. For instance, consider this figure from one of Marshall's papers:

Making gradient bars and all the lines and annotations would be a nightmare to do via script (and this isn't even very complicated). Yes, if you decide to make a change, you will have to redo some manual work in Illustrator, hence the common wisdom to make it all in scripts to "save time redoing things". But given the amount of effort it takes to figure out how to code that stuff, nine times out of ten, the total amount of time spent just redoing it will be less. And in a time when nobody reads things carefully, adding all these visual elements to your paper to make it easier to explain your work quickly is a strong imperative–stronger than making sure it all comes from a script, in my view.
Anyway, all that said, what do we actually do in the lab? Having gone through a couple iterations, we've basically settled on the following. We make a Dropbox folder for the paper, and within the folder, we have subfolders, one for raw(ish) data, one for scripts, one for graphs and one for figures (perhaps with some elaborations depending on circumstances). In the scripts folder is a set of, uh, scripts that, when run, take the raw(ish) data and turn it into the graphical elements. We then assemble those graphical elements into figures, along with a readme file to document which files went into the figure. Those figures can contain heavily altered versions of the graphical elements, and we will typically adjust font sizes, ticks, colors, you name it, but if you want to figure out why some data point was where it was, the chain is fully accessible. Then, when we're done, we put the files all into bitbucket for anyone to access.
Oh, and one other thing about permanence: our scripts use some combination of R and MATLAB, and they work for now. They may not work forever. That's fine. Life goes on, and most papers don't. Those that do do so because of their scientific conclusions, not their data or analysis per se. So I'm not worried about it.
Update, 3/1/2016: Pretty predictable pushback from a lot of people, especially about version control. First, just to reiterate, we use version control for our general purpose tools, which are edited and used by many people, thus making version control the right tool for the job. Still, I have yet to hear any truly compelling arguments for using version control that would mitigate against the substantial associated complexity for the use case I am discussing here, which is making the analyses in a paper reproducible. There's a lot of bald assertions of the benefits of version control out there without any real evidence for their validity other than "well, I think this should be better", also with little frank discussion of the hassles of version control. This strikes me as similar to the pushback against the LaTeX vs. Word paper. Evidence be damned! :)
It's no secret that biomedical research is requiring more and more computational analyses these days, and with that has come some welcome discussion of how to make those analyses reproducible. On some level, I guess it's a no-brainer: if it's not reproducible, it's not science, right? And on a practical level, I think there are a lot of good things about making your analysis reproducible, including the following (vaguely ranked starting with what I consider most important):
- Umm, that it’s reproducible.
- It makes you a bit more careful about making your code more likely to be right, cleaner, and readable to others.
- This in turn makes it easier for others in the lab to access and play with the analyses and data in the future, including the PI.
- It could be useful for others outside the lab, although as I’ve said before, I think the uses for our data outside our lab are relatively limited beyond the scientific conclusions we have made. Still, whatever, it’s there if you want it. I also freely admit this might be more important for people who do work other people actually care about. :)
- It takes a lot of time.
My worry, however, is that the strategies for reproducibility that computational types are often promoting are off-target and not necessarily adapted for the needs and skills of the people they are trying to reach. There is a certain strain of hyper-reproducible zealotry that I think is discouraging others to adopt some basic practices that could greatly benefit their research, and at the same time is limiting the productivity of even its own practitioners. You know what I'm talking about: it's the idea of turning your entire paper into a program, so you just type "make paper" and out pops the fully formed and formatted manuscript. Fine in the abstract, but in a line of work (like many others) in which time is our most precious commodity, these compulsions represent a complete failure to correctly measure opportunity costs. In other words, instead of hard coding the adjustment of the figure spacing of your LaTeX preprint, spend that time writing another paper. I think it’s really important to remember that our job is science, not programming, and if we focus too heavily on the procedural aspects of making everything reproducible and fully documented, we risk turning off those who are less comfortable with programming from the very real benefits of making their analysis reproducible.
Here are the two biggest culprits in my view: version control and figure scripting.
Let's start with version control. I think we can all agree that the most important part of making a scientific analysis reproducible is to make sure the analysis is in a script and not just typed or clicked into a program somewhere, only for those commands to vanish into faded memory. A good, reproducible analysis script should start with raw data, go through all the computational manipulations required, and leave you with a number or graphical element that ends up in your paper somewhere. This makes the analysis reproducible, because someone else can now just run the code and see how your raw data turned into that p-value in subpanel Figure 4G. And remember, that someone else is most likely your future self :).
Okay, so we hopefully all agree on the need for scripts. Then, however, almost every discussion about computational reproducibility begins with a directive to adopt git or some other version control system, as though it’s the obvious next step. Hmm. I’m just going to come right out and say that for the majority of computational projects (at least in our lab), version control is a waste of time. Why? Well, what is the goal of making a reproducible analysis? I believe the goal is to have a documented set of scripts that take raw data and reliably turn it into a bit of knowledge of some kind. The goal of version control is to manage code, in particular emphasizing “reversibility, concurrency, and annotation [of changes to code]”. While one can imagine some overlap between these goals, I don’t necessarily see a natural connection between them. To make that more concrete, let’s try to answer the question that I’ve been asking (and been asked), which is “Why not just use Dropbox?”. After all, Dropbox will keep all your code and data around (including older versions), shared between people seamlessly, and probably will only go down if WWIII breaks out. And it's easy to use. Here are a few potential arguments I can imagine people might make in favor of version control:
- You can avoid having Fig_1.ai, Fig_1_2.ai, Fig_1_2_final_AR_PG_JK.ai, etc. Just make the change and commit! You have all the old versions!
- You can keep track of who changed what code and roll things back (and manage file conflicts).
Which brings us then to point 2, about tracking code changes. In thinking about this, I think it’s useful to separate out code that is for general purpose tools in the lab and code that is specific for a particular project. For code for general purpose tools that multiple team members are contributing to, version control makes a lot of sense–that’s what it was really designed for, after all. It’s very helpful to see older versions of the codebase, see the exact changes that other members of the team have made, and so forth.
These rationales don’t really apply, though, to code that people will write for analyzing data for a particular project. In our lab, and I suspect most others, this code is typically written by one or two people, and if two, they’re typically working in very close contact. Moreover, the end goal is not to have a record of a shifting codebase, but rather to have a single, finalized set of analysis scripts that will reproduce the figures and numbers in the paper. For this reason, the ability to roll back to previous versions of the code and annotate changes is of little utility in practice. I asked around lab, and I think there was maybe one time when we rolled back code. Otherwise, basically, for most analyses for papers, we just move forward and don’t worry about it. I suppose there is theoretically the possibility that some old analysis could prove useful that you could recover through version control, but honestly, most of the time, that ends up in a separate folder anyway. (One might say that’s not clean, but I think that it’s actually just fine. If an analysis is different in kind, then replacing it via version control doesn’t really make sense–it’s not a replacement of previous code per se.)
Of course, one could say, well, even if version control isn’t strictly necessary for reproducible analyses, what does it hurt? In my opinion, the big negative is the amount of friction version control injects into virtually every aspect of the analysis process. This is the price you pay for versioning and annotation, and I think there’s no way to get around that. With Dropbox, I just stick a file in and it shows up everywhere, up to date, magically. No muss, no fuss. If you use version control, it’s constant committing, pushing, pulling, updating, and adding notes. Moreover, if you’re like me, you will screw up at some point, leading to some problem, potentially catastrophic, that you will spend hours trying to figure out. I’m clearly not alone:

Oh, and I think there are some people who use version control for the text of their papers (almost certainly a proper subset of those who are for some reason writing their papers in Markdown or LaTeX). Unless your paper has a lot of math in it, I have no idea why anyone would subject themselves to this form of torture. Let me be the one to tell you that you are no less smart or tough if you use Google Docs. In fact, some might say you’re more smart, because you don’t let command-line ethos/ideology get in the way of actually getting things done… :)
Which brings me to the example of figure scripting. Figure scripting is the process of making a figure completely from a script. Such a script will make all the subpanels, adjust all the font sizes, deal with all the colors, and so forth. In an ideal world with infinite time, this would be great–who wouldn't want to make all their figures magically appear by typing make figures? In practice, there are definitely some diminishing returns, and it's up to you where the line is between making it reproducible and getting it done. For me, the hard line is that all graphical elements representing data values should be coded. Like, if I make a scatterplot, then the locations of the points relatively to axes should be hard coded. Beyond that, Illustrator time! Illustrator will let you set the font size, the line weighting, marker color, and virtually every other thing you can think of simply and relatively intuitively, with immediate feedback. If you can set your font sizes and so forth programmatically, more power to you. But it's worth keeping in mind that the time you spend programming these things is time you could be spending on something else. This time can be substantial: check out this lengthy bit of code written to avoid a trip to Illustrator. Also, as the complexity of what you're trying to do gets greater, the fewer packages there are to help you make your figure. For instance, consider this figure from one of Marshall's papers:

Making gradient bars and all the lines and annotations would be a nightmare to do via script (and this isn't even very complicated). Yes, if you decide to make a change, you will have to redo some manual work in Illustrator, hence the common wisdom to make it all in scripts to "save time redoing things". But given the amount of effort it takes to figure out how to code that stuff, nine times out of ten, the total amount of time spent just redoing it will be less. And in a time when nobody reads things carefully, adding all these visual elements to your paper to make it easier to explain your work quickly is a strong imperative–stronger than making sure it all comes from a script, in my view.
Anyway, all that said, what do we actually do in the lab? Having gone through a couple iterations, we've basically settled on the following. We make a Dropbox folder for the paper, and within the folder, we have subfolders, one for raw(ish) data, one for scripts, one for graphs and one for figures (perhaps with some elaborations depending on circumstances). In the scripts folder is a set of, uh, scripts that, when run, take the raw(ish) data and turn it into the graphical elements. We then assemble those graphical elements into figures, along with a readme file to document which files went into the figure. Those figures can contain heavily altered versions of the graphical elements, and we will typically adjust font sizes, ticks, colors, you name it, but if you want to figure out why some data point was where it was, the chain is fully accessible. Then, when we're done, we put the files all into bitbucket for anyone to access.
Oh, and one other thing about permanence: our scripts use some combination of R and MATLAB, and they work for now. They may not work forever. That's fine. Life goes on, and most papers don't. Those that do do so because of their scientific conclusions, not their data or analysis per se. So I'm not worried about it.
Update, 3/1/2016: Pretty predictable pushback from a lot of people, especially about version control. First, just to reiterate, we use version control for our general purpose tools, which are edited and used by many people, thus making version control the right tool for the job. Still, I have yet to hear any truly compelling arguments for using version control that would mitigate against the substantial associated complexity for the use case I am discussing here, which is making the analyses in a paper reproducible. There's a lot of bald assertions of the benefits of version control out there without any real evidence for their validity other than "well, I think this should be better", also with little frank discussion of the hassles of version control. This strikes me as similar to the pushback against the LaTeX vs. Word paper. Evidence be damned! :)
Sunday, August 23, 2015
Top 10 signs that a paper/field is bogus
These days, there has been a lot of hang-wringing about how most papers and wrong and reproducibility and so forth. Often this is accompanied with some shrill statements like “There’s a crisis in the biomedical research system! Everything is broken! Will somebody please think of the children?!” And look, I agree that these are all Very Bad Things. The question is what to do about it. There are some (misguided, in my view) reproducibility efforts out there, with things like registered replication studies and publishing all negative results and so forth. I don’t really have too much to say about all that except that it seems like a pretty boring sort of science to do.
So what to do about this supposed crisis? I remember someone I know telling me that when he was in graduate school, he went to his (senior, pretty famous) PI with a bunch of ideas based on what he'd been reading, and the PI said something along the lines of "Look, don't confuse yourself by reading too much of that stuff, most of it’s wrong anyway". I've been thinking for some time now that this is some of the best advice you can get.
Of course, that PI had decades of experience to draw upon, whereas the trainee obviously didn't. And I meet a lot of trainees these days who believe in all kinds of crazy things. I think that learning how to filter out what is real from the ocean of scientific literature is a skill that hopefully most trainees get some exposure to during their science lives. That said, there’s precious little formalized advice out there for trainees on this point, and I believe that a little knowledge can go a long way: for trainees, following up on a bogus result can lead to years of wasted time. Even worse is choosing a lab that works on a bogus field–a situation from which escape is difficult. So I actually think it is fair to ask “Will somebody please think of the trainees?”.
With this in mind, I thought it might be useful to share some of the things I've learned over the last several years. A lot of this is very specific to molecular biology, but maybe useful beyond. Sadly, I’ll be omitting concrete examples for obvious reasons, but buy me a beer sometime and then maybe I'll spill the beans. If you’re looking for a general principle underlying these thoughts, it’s to have a very strong underlying belief system based in Golden Era molecular biology. Like: DNA replication, yeah, I’m pretty sure that’s a thing. Golgi Apparatus, I think that exists. Transcription and translation, pretty sure those really happen. Beyond that, well…
So what to do about this supposed crisis? I remember someone I know telling me that when he was in graduate school, he went to his (senior, pretty famous) PI with a bunch of ideas based on what he'd been reading, and the PI said something along the lines of "Look, don't confuse yourself by reading too much of that stuff, most of it’s wrong anyway". I've been thinking for some time now that this is some of the best advice you can get.
Of course, that PI had decades of experience to draw upon, whereas the trainee obviously didn't. And I meet a lot of trainees these days who believe in all kinds of crazy things. I think that learning how to filter out what is real from the ocean of scientific literature is a skill that hopefully most trainees get some exposure to during their science lives. That said, there’s precious little formalized advice out there for trainees on this point, and I believe that a little knowledge can go a long way: for trainees, following up on a bogus result can lead to years of wasted time. Even worse is choosing a lab that works on a bogus field–a situation from which escape is difficult. So I actually think it is fair to ask “Will somebody please think of the trainees?”.
With this in mind, I thought it might be useful to share some of the things I've learned over the last several years. A lot of this is very specific to molecular biology, but maybe useful beyond. Sadly, I’ll be omitting concrete examples for obvious reasons, but buy me a beer sometime and then maybe I'll spill the beans. If you’re looking for a general principle underlying these thoughts, it’s to have a very strong underlying belief system based in Golden Era molecular biology. Like: DNA replication, yeah, I’m pretty sure that’s a thing. Golgi Apparatus, I think that exists. Transcription and translation, pretty sure those really happen. Beyond that, well…
- Run the numbers. One consistent issue in molecular biology is that because it tends to be so qualitative, we have little sense for magnitudes and plausibility of various mechanisms. That said, we now are getting to the point where we have a lot more quantitative data that lets us run some basic sanity checks (BioNumbers is a great resource for this). An example that I’ve come across often is mRNA localization. Many people I’ve met have, umm, fairly fanciful notions of the degree to which mRNA is localized. From what we’ve seen in the lab, almost every mRNA seems to just be randomly distributed around the cytoplasm, with the exception being ER-localized ones, which are, well, localized to the ER. Ask yourself: why should there be any mRNA localization? Numbers indicate that proteins diffuse quite rapidly around the cell, on a timescale that is likely faster than mRNA transport. So for most cells, the numbers say that you shouldn’t localize mRNA–rather, just localize proteins. And, uh, that’s what we see. There are of course exceptions, like lncRNA, that show interesting localization patterns–again, this makes sense because there is no protein to localize downstream. There are other things that people say about lncRNA that don’t make sense, though. I’ll leave that as an exercise for the reader… :) (Also should point out that these considerations can actually help make the case for mRNA localization in neurons, which I think is a thing.)
- Consider why nobody has seen this Amazing New Phenomenon before. Was it a lack of technology? Okay, then it might be real. Was it just brute force? Also possible that it's real. Was it just waiting for someone to think of the idea? Well, in my experience, nutty ideas are relatively cheap. So I'd be very suspicious if this result was just apparently sitting there without anyone noticing. Ask yourself: should this putative set of genes have shown up in a genetic screen? Should this protein have co-purified with this other protein? Did people already do similar experiments a long time ago and come up empty handed? What are other situations in which people may have inadvertently seen the same thing before? It’s also possible that the result is indeed true, but represents a “one-off” special case: consider this exchange about a recent paper (I have to say that I was surprised that some people in the lab didn’t even find this result surprising!). Whether you choose to pursue one-offs is I think a largely aesthetic choice.
- Trust your brain, not stats. If looking at an effect makes you wonder what the p-value is, you’re already on thin ice, so tread carefully. Also, beware of new statistical methods that claim to extract results from the same data where none existed before. Usually, these will at best find only marginally interesting new examples. More often, they just find noise. If there was something really obvious, probably the original authors would have found it by manual inspection of the data. Also, if there’s a clear confounding factor that the authors claim to have somehow controlled for, be suspicious.
- Beware of the "dynamic process". Sometimes, when you press someone on the details of a particular entity or process in the cell whose existence is dubious, they will respond with "Well, it's a dynamic object/process." Often (though certainly not always), this is an excuse for lazy thinking. Remember that just because something is "dynamic" doesn't mean that you should not be able to see it! Equilibrium, people.
- For some crazy new proposed mechanism, ask yourself if that is how you think the cell would do it. We often hear that nothing in biology makes sense except in light of evolution. In this context, I think it's worth wondering whether the proposed mechanism would be a reasonable way for the cell to do something it was not otherwise able to do. Otherwise, maybe it’s some sort of artifact. As a (made up) example, cells have many well-established mechanisms for communicating with each other. For a new mechanism of communication to be plausible (in my book), it should offer some additional functionality beyond these existing mechanisms. Evolution can do weird stuff, though, so this line of reasoning is inherently somewhat suspect.
- Check for missing obvious-next-step experiments. Sometimes you’ll find a paper describing something cool and new, and you’ll immediately wonder “Hmm, if what they’re saying is true, then shouldn’t those particles also be able to…”. Well, if you thought of it after reading a paper for 30 minutes, then presumably the authors had the same idea as some point as well. And presumably tried it. And it presumably didn’t work. (Oh, wait, sorry, I meant the results were “inconclusive”.) Or they tried to get RNA from those cells to profile. And they just didn’t get enough RNA. And so on. Keep an eye out for these, especially if multiple papers are missing these key experiments.
- For methods, look for validation with known biology. The known positives should be positive and presumed negatives should be negative. Let’s say you have some new sequencing method for measuring all RNA-protein interactions (again, completely hypothetical). Have a list of known interactions that should show up and a list of ones for which there’s no plausible reason to expect an interaction. Most people think about the positives, but less often about the negatives. Think carefully about them.
- Dig carefully into validation studies. I remember reading some paper in which they claimed to have detected a bunch of new molecules and then “validated” their existence. Then the validation had things like blots exposed for weeks to show signals and PCRs run for 80 cycles and stuff like that. Hmm. Often this data is buried deep in supplements. Spend the time to find it.
- Be suspicious of the interpretation of biological perturbations. Cells are hard to manipulate. And so it’s perhaps unsurprising that most perturbations can lead you astray. Off-target effects for knockdown are notoriously difficult to control for. And even if you do have target specificity, another problem is that as our measurements get better, biological complexity means that virtually all hypotheses will be true at least 50% of the time. Overexpression often leads to hugely non-biological protein levels and can lead to artifacts. Cloning out single cells leads to weird variability. Frankly, playing with cells is so difficult that I’m sort of amazed we understand anything!
- Know the limitations of methods. If you’re looking for differential gene expression, how much can you trust RT-PCR? Have you heard of the MIQE guidelines for RT-PCR? I hadn't, but they are extensive. For RNA-seq, how well-validated is it in your expression regime? If you’re analyzing sequence variants, how do you know it’s not sequencing error (since largely discredited claims of extensive RNA editing are one widely-publicized example of this issue). ChIP-seq hotspots? The list goes on. If you don’t know much about a method, ask someone who does.
- Bonus: autofluorescence. Enough said.
I offer these more as a set of guidelines for how I like to think about new results, and I’m sure we can all think of several counterexamples to virtually every one of these. My point is that high-level thinking in molecular biology requires making decisions, and making a real decision means leaving something else on the table. Making decisions based on the literature means deciding what avenues not to follow up on, and I think that most good molecular biologists learn this early on. Even more importantly, they develop the social networks to get the insider’s perspective on what to trust and what to ignore. As a beginning trainee, though, you typically will have neither the experience nor the network to make these decisions. My advice would be to pick a PI who asks these same sorts of questions. Then keep asking yourself these questions during your training. Seek out critical people and bounce your ideas off of them. At the same time, don’t become one of those people who just rips every paper to shreds in journal club. The point is to learn to exhibit sound judgement and find a way forward, and that also means sifting out the good nuggets and threading them together across multiple papers.
As a related point, as I mentioned earlier, there’s a lot of fuss out there about the “reproducibility crisis”. There’s two possible models: one in which we require every paper to be “true”, and the more laissez-faire model I am advocating for in which we just assume a lot of papers are wrong and train people to know the difference. Annoying reviewers often say that extraordinary claims require extraordinary evidence. I think this is wrong, and I’m not alone (hat tip: Dynamic Ecology). I think that in any one paper, you do your best, and time will tell whether you were right or wrong. It’s just not practical or efficient for a paper to solve every potential problem, with every result cross-validated with every method. Science is bigger than any one paper, and I think it’s worth providing our trainees with a better appreciation of that fact.
Update, 8/25/2015:
Couple nice suggestions from various folks. One from anonymous suggests "#12: Whenever the word 'modulating' appears anywhere in title/abstract." Well said!
Another point from Casey Bergman:
As a related point, as I mentioned earlier, there’s a lot of fuss out there about the “reproducibility crisis”. There’s two possible models: one in which we require every paper to be “true”, and the more laissez-faire model I am advocating for in which we just assume a lot of papers are wrong and train people to know the difference. Annoying reviewers often say that extraordinary claims require extraordinary evidence. I think this is wrong, and I’m not alone (hat tip: Dynamic Ecology). I think that in any one paper, you do your best, and time will tell whether you were right or wrong. It’s just not practical or efficient for a paper to solve every potential problem, with every result cross-validated with every method. Science is bigger than any one paper, and I think it’s worth providing our trainees with a better appreciation of that fact.
Update, 8/25/2015:
Couple nice suggestions from various folks. One from anonymous suggests "#12: Whenever the word 'modulating' appears anywhere in title/abstract." Well said!
Another point from Casey Bergman:
Lemaitre: be skeptical of results where there is a big paper with no follow-up #wtdros14
— Casey Bergman (@caseybergman) August 2, 2014
Subscribe to:
Posts (Atom)